 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Transfer Learning for Contextual Reinforcement Learning
Paper and Code
Aug 08, 2024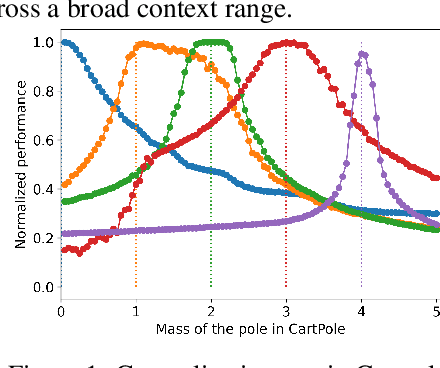
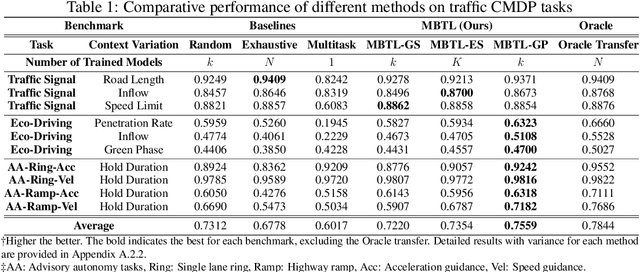
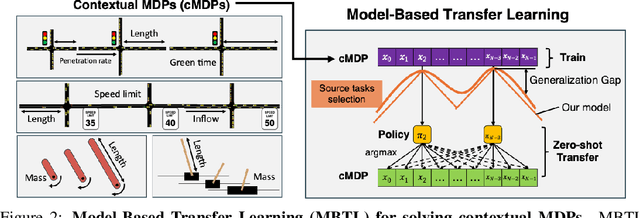
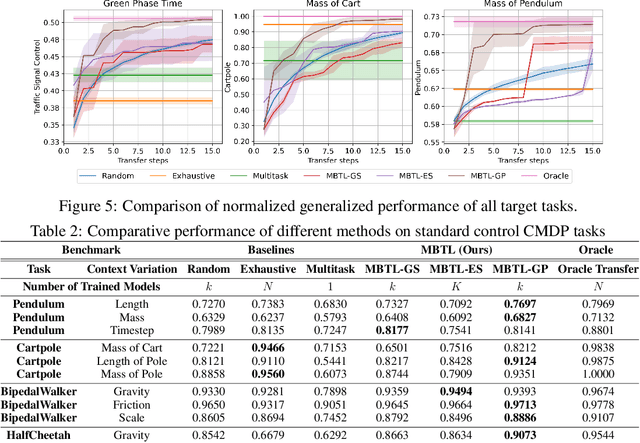
Deep reinforcement learning is a powerful approach to complex decision making. However, one issue that limits its practical application is its brittleness, sometimes failing to train in the presence of small changes in the environment. This work is motivated by the empirical observation that directly applying an already trained model to a related task often works remarkably well, also called zero-shot transfer. We take this practical trick one step further to consider how to systematically select good tasks to train, maximizing overall performance across a range of tasks. Given the high cost of training, it is critical to choose a small set of training tasks. The key idea behind our approach is to explicitly model the performance loss (generalization gap) incurred by transferring a trained model. We hence introduce Model-Based Transfer Learning (MBTL) for solving contextual RL problems. In this work, we model the performance loss as a simple linear function of task context similarity. Furthermore, we leverage Bayesian optimization techniques to efficiently model and estimate the unknown training performance of the task space. We theoretically show that the method exhibits regret that is sublinear in the number of training tasks and discuss conditions to further tighten regret bounds. We experimentally validate our methods using urban traffic and standard control benchmarks. Despite the conceptual simplicity, the experimental results suggest that MBTL can achieve greater performance than strong baselines, including exhaustive training on all tasks, multi-task training, and random selection of training tasks. This work lays the foundations for investigating explicit modeling of generalization, thereby enabling principled yet effective methods for contextual RL.