 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperationalising the Right to be Forgotten in LLMs: A Lightweight Sequential Unlearning Framework for Privacy-Aligned Deployment in Politically Sensitive Environments
Apr 14, 2026Large Language Models (LLMs) are increasingly deployed in politically sensitive environments, where memorisation of personal data or confidential content raises regulatory concerns under frameworks such as the GDPR and its Right to be Forgotten. Translating such legal principles into large-scale generative systems presents significant technical challenges. We introduce a lightweight sequential unlearning framework that explicitly separates retention and suppression objectives. The method first stabilises benign capabilities through positive fine-tuning, then applies layer-restricted negative fine-tuning to suppress designated sensitive patterns while preserving general language competence. Experiments on the SemEval-2025 LLM Unlearning benchmark demonstrate effective behavioural suppression with minimal impact on factual accuracy and fluency. GPT-2 exhibits greater robustness than DistilGPT-2, highlighting the role of model capacity in privacy-aligned adaptation. We position sequential unlearning as a practical and reproducible mechanism for operationalising data erasure requirements in politically deployed LLMs.
* 10 pages
Towards Explainable Job Title Matching: Leveraging Semantic Textual Relatedness and Knowledge Graphs
Sep 11, 2025Semantic Textual Relatedness (STR) captures nuanced relationships between texts that extend beyond superficial lexical similarity. In this study, we investigate STR in the context of job title matching - a key challenge in resume recommendation systems, where overlapping terms are often limited or misleading. We introduce a self-supervised hybrid architecture that combines dense sentence embeddings with domain-specific Knowledge Graphs (KGs) to improve both semantic alignment and explainability. Unlike previous work that evaluated models on aggregate performance, our approach emphasizes data stratification by partitioning the STR score continuum into distinct regions: low, medium, and high semantic relatedness. This stratified evaluation enables a fine-grained analysis of model performance across semantically meaningful subspaces. We evaluate several embedding models, both with and without KG integration via graph neural networks. The results show that fine-tuned SBERT models augmented with KGs produce consistent improvements in the high-STR region, where the RMSE is reduced by 25% over strong baselines. Our findings highlight not only the benefits of combining KGs with text embeddings, but also the importance of regional performance analysis in understanding model behavior. This granular approach reveals strengths and weaknesses hidden by global metrics, and supports more targeted model selection for use in Human Resources (HR) systems and applications where fairness, explainability, and contextual matching are essential.
Advancing Earth Observation: A Survey on AI-Powered Image Processing in Satellites
Jan 21, 2025Advancements in technology and reduction in it's cost have led to a substantial growth in the quality & quantity of imagery captured by Earth Observation (EO) satellites. This has presented a challenge to the efficacy of the traditional workflow of transmitting this imagery to Earth for processing. An approach to addressing this issue is to use pre-trained artificial intelligence models to process images on-board the satellite, but this is difficult given the constraints within a satellite's environment. This paper provides an up-to-date and thorough review of research related to image processing on-board Earth observation satellites. The significant constraints are detailed along with the latest strategies to mitigate them.
Predicting Country Instability Using Bayesian Deep Learning and Random Forest
Nov 11, 2024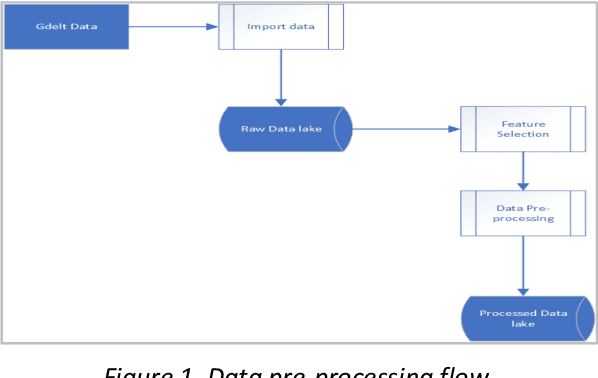
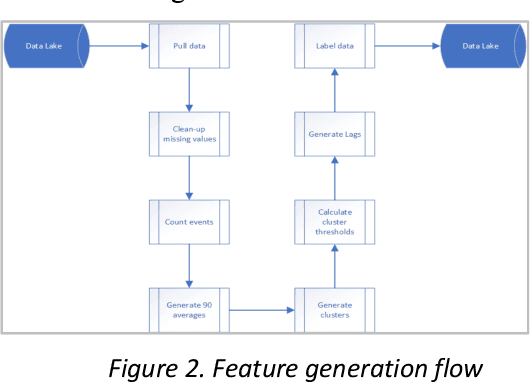
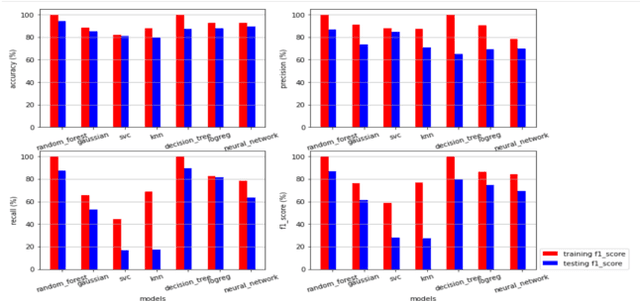
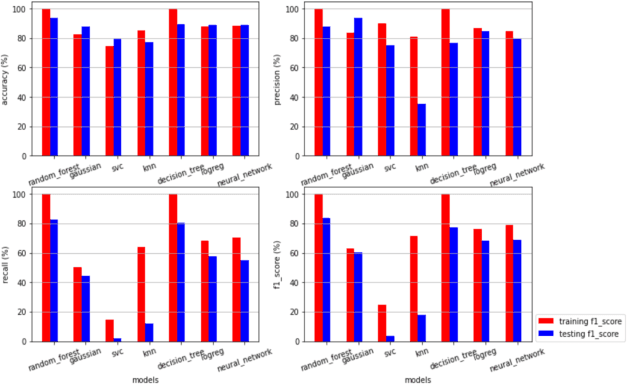
Country instability is a global issue, with unpredictably high levels of instability thwarting socio-economic growth and possibly causing a slew of negative consequences. As a result, uncertainty prediction models for a country are becoming increasingly important in the real world, and they are expanding to provide more input from 'big data' collections, as well as the interconnectedness of global economies and social networks. This has culminated in massive volumes of qualitative data from outlets like television, print, digital, and social media, necessitating the use of artificial intelligence (AI) tools like machine learning to make sense of it all and promote predictive precision [1]. The Global Database of Activities, Voice, and Tone (GDELT Project) records broadcast, print, and web news in over 100 languages every second of every day, identifying the people, locations, organisations, counts, themes, outlets, and events that propel our global community and offering a free open platform for computation on the entire world. The main goal of our research is to investigate how, when our data grows more voluminous and fine-grained, we can conduct a more complex methodological analysis of political conflict. The GDELT dataset, which was released in 2012, is the first and potentially the most technologically sophisticated publicly accessible dataset on political conflict.
GASE: Generatively Augmented Sentence Encoding
Nov 07, 2024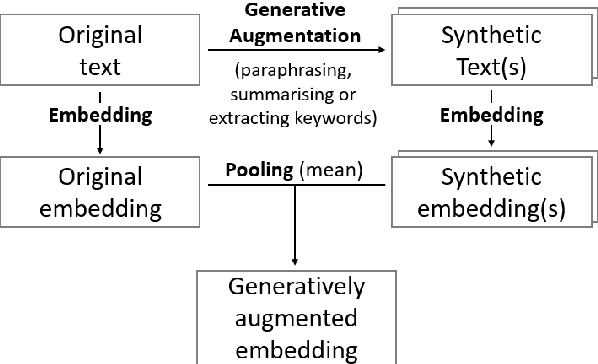
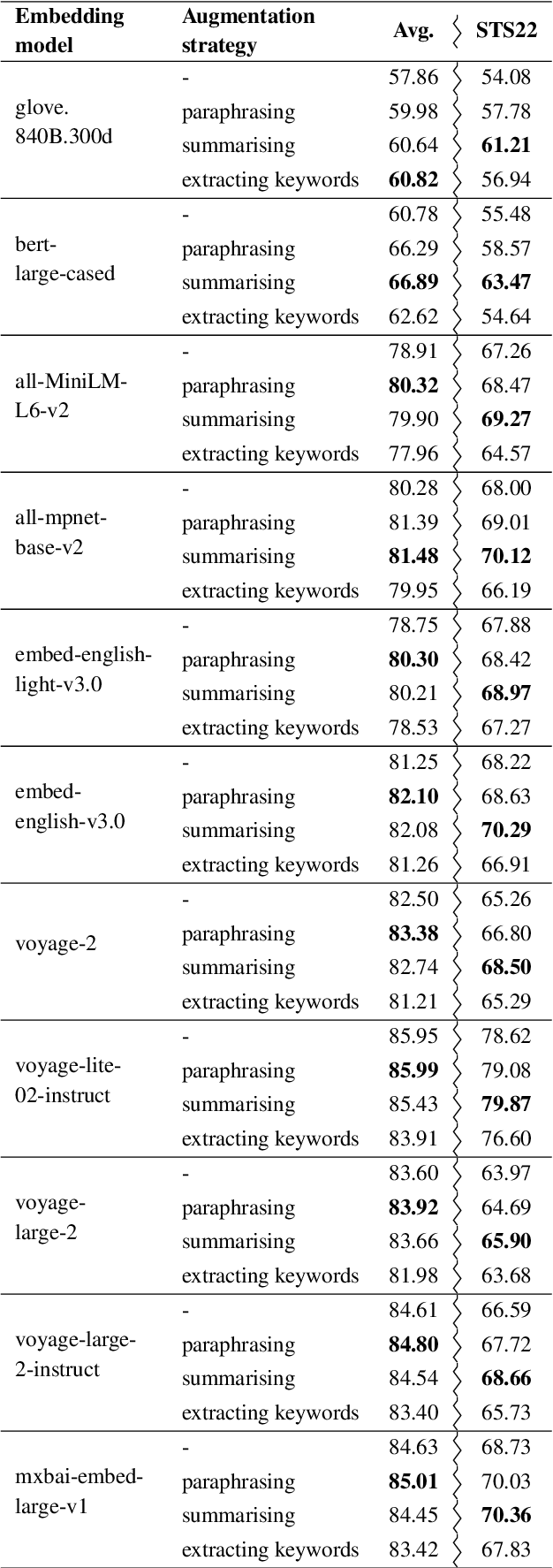
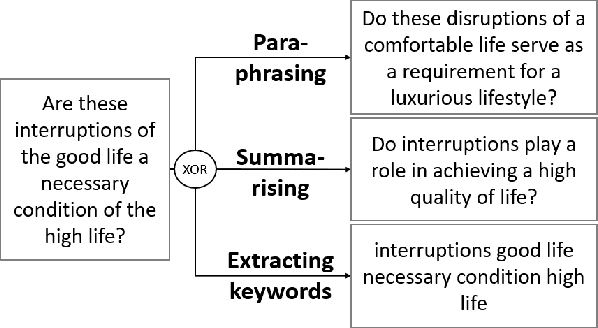
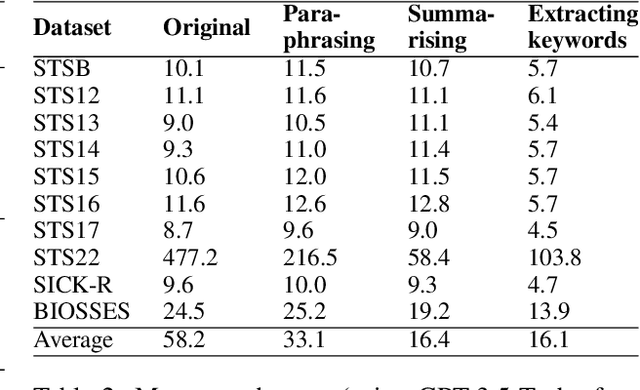
We propose an approach to enhance sentence embeddings by applying generative text models for data augmentation at inference time. Unlike conventional data augmentation that utilises synthetic training data, our approach does not require access to model parameters or the computational resources typically required for fine-tuning state-of-the-art models. Generatively Augmented Sentence Encoding uses diverse linguistic synthetic variants of input texts generated by paraphrasing, summarising, or extracting keywords, followed by pooling the original and synthetic embeddings. Experimental results on the Massive Text Embedding Benchmark for Semantic Textual Similarity (STS) demonstrate performance improvements across a range of embedding models using different generative models for augmentation. We find that generative augmentation leads to larger performance improvements for embedding models with lower baseline performance. These findings suggest that integrating generative augmentation at inference time adds semantic diversity and can enhance the robustness and generalizability of sentence embeddings for embedding models. Our results show that the degree to which generative augmentation can improve STS performance depends not only on the embedding model but also on the dataset. From a broader perspective, the approach allows trading training for inference compute.
gaHealth: An English-Irish Bilingual Corpus of Health Data
Mar 06, 2024
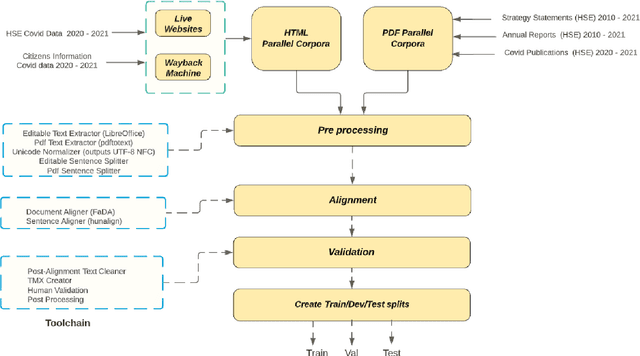
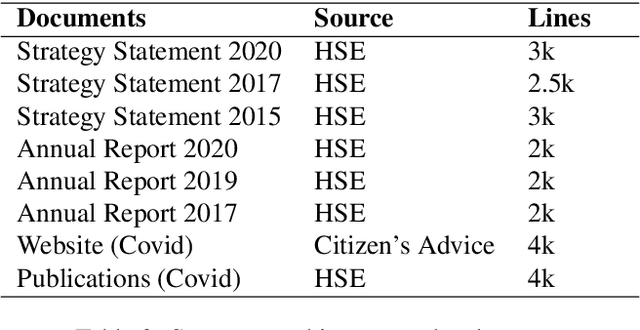
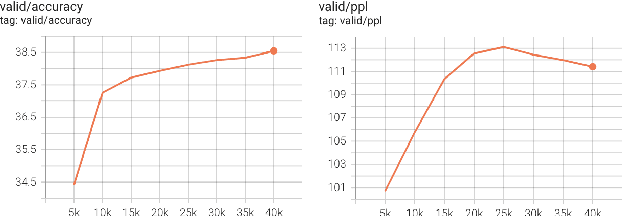
Machine Translation is a mature technology for many high-resource language pairs. However in the context of low-resource languages, there is a paucity of parallel data datasets available for developing translation models. Furthermore, the development of datasets for low-resource languages often focuses on simply creating the largest possible dataset for generic translation. The benefits and development of smaller in-domain datasets can easily be overlooked. To assess the merits of using in-domain data, a dataset for the specific domain of health was developed for the low-resource English to Irish language pair. Our study outlines the process used in developing the corpus and empirically demonstrates the benefits of using an in-domain dataset for the health domain. In the context of translating health-related data, models developed using the gaHealth corpus demonstrated a maximum BLEU score improvement of 22.2 points (40%) when compared with top performing models from the LoResMT2021 Shared Task. Furthermore, we define linguistic guidelines for developing gaHealth, the first bilingual corpus of health data for the Irish language, which we hope will be of use to other creators of low-resource data sets. gaHealth is now freely available online and is ready to be explored for further research.
* arXiv admin note: text overlap with arXiv:2403.02367
Design of an Open-Source Architecture for Neural Machine Translation
Mar 06, 2024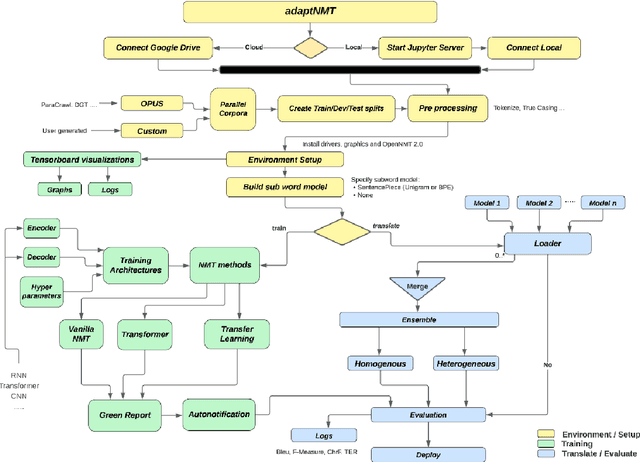
adaptNMT is an open-source application that offers a streamlined approach to the development and deployment of Recurrent Neural Networks and Transformer models. This application is built upon the widely-adopted OpenNMT ecosystem, and is particularly useful for new entrants to the field, as it simplifies the setup of the development environment and creation of train, validation, and test splits. The application offers a graphing feature that illustrates the progress of model training, and employs SentencePiece for creating subword segmentation models. Furthermore, the application provides an intuitive user interface that facilitates hyperparameter customization. Notably, a single-click model development approach has been implemented, and models developed by adaptNMT can be evaluated using a range of metrics. To encourage eco-friendly research, adaptNMT incorporates a green report that flags the power consumption and kgCO${_2}$ emissions generated during model development. The application is freely available.
* arXiv admin note: substantial text overlap with arXiv:2403.02367
adaptNMT: an open-source, language-agnostic development environment for Neural Machine Translation
Mar 04, 2024adaptNMT streamlines all processes involved in the development and deployment of RNN and Transformer neural translation models. As an open-source application, it is designed for both technical and non-technical users who work in the field of machine translation. Built upon the widely-adopted OpenNMT ecosystem, the application is particularly useful for new entrants to the field since the setup of the development environment and creation of train, validation and test splits is greatly simplified. Graphing, embedded within the application, illustrates the progress of model training, and SentencePiece is used for creating subword segmentation models. Hyperparameter customization is facilitated through an intuitive user interface, and a single-click model development approach has been implemented. Models developed by adaptNMT can be evaluated using a range of metrics, and deployed as a translation service within the application. To support eco-friendly research in the NLP space, a green report also flags the power consumption and kgCO$_{2}$ emissions generated during model development. The application is freely available.
Transformers for Low-Resource Languages:Is Féidir Linn!
Mar 04, 2024The Transformer model is the state-of-the-art in Machine Translation. However, in general, neural translation models often under perform on language pairs with insufficient training data. As a consequence, relatively few experiments have been carried out using this architecture on low-resource language pairs. In this study, hyperparameter optimization of Transformer models in translating the low-resource English-Irish language pair is evaluated. We demonstrate that choosing appropriate parameters leads to considerable performance improvements. Most importantly, the correct choice of subword model is shown to be the biggest driver of translation performance. SentencePiece models using both unigram and BPE approaches were appraised. Variations on model architectures included modifying the number of layers, testing various regularisation techniques and evaluating the optimal number of heads for attention. A generic 55k DGT corpus and an in-domain 88k public admin corpus were used for evaluation. A Transformer optimized model demonstrated a BLEU score improvement of 7.8 points when compared with a baseline RNN model. Improvements were observed across a range of metrics, including TER, indicating a substantially reduced post editing effort for Transformer optimized models with 16k BPE subword models. Bench-marked against Google Translate, our translation engines demonstrated significant improvements. The question of whether or not Transformers can be used effectively in a low-resource setting of English-Irish translation has been addressed. Is f\'eidir linn - yes we can.
* 13 pages
adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds
Mar 04, 2024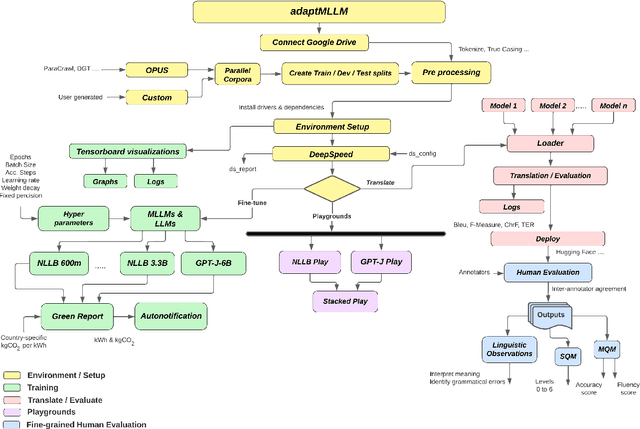

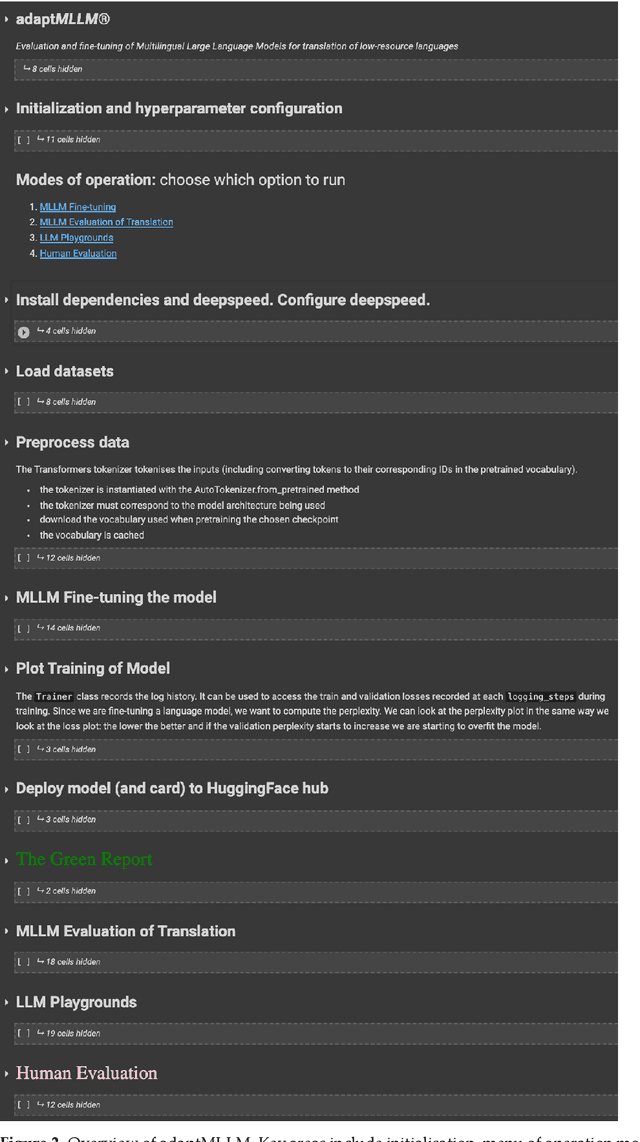
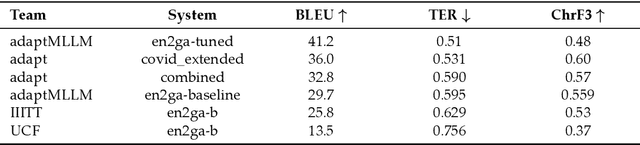
The advent of Multilingual Language Models (MLLMs) and Large Language Models has spawned innovation in many areas of natural language processing. Despite the exciting potential of this technology, its impact on developing high-quality Machine Translation (MT) outputs for low-resource languages remains relatively under-explored. Furthermore, an open-source application, dedicated to both fine-tuning MLLMs and managing the complete MT workflow for low-resources languages, remains unavailable. We aim to address these imbalances through the development of adaptMLLM, which streamlines all processes involved in the fine-tuning of MLLMs for MT. This open-source application is tailored for developers, translators, and users who are engaged in MT. An intuitive interface allows for easy customisation of hyperparameters, and the application offers a range of metrics for model evaluation and the capability to deploy models as a translation service directly within the application. As a multilingual tool, we used adaptMLLM to fine-tune models for two low-resource language pairs: English to Irish (EN$\leftrightarrow$GA) and English to Marathi (EN$\leftrightarrow$MR). Compared with baselines from the LoResMT2021 Shared Task, the adaptMLLM system demonstrated significant improvements. In the EN$\rightarrow$GA direction, an improvement of 5.2 BLEU points was observed and an increase of 40.5 BLEU points was recorded in the GA$\rightarrow$EN direction. Significant improvements in the translation performance of the EN$\leftrightarrow$MR pair were also observed notably in the MR$\rightarrow$EN direction with an increase of 21.3 BLEU points. Finally, a fine-grained human evaluation of the MLLM output on the EN$\rightarrow$GA pair was conducted using the Multidimensional Quality Metrics and Scalar Quality Metrics error taxonomies. The application and models are freely available.