 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGASE: Generatively Augmented Sentence Encoding
Nov 07, 2024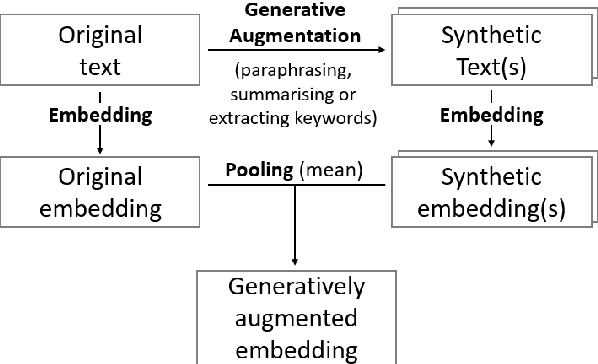
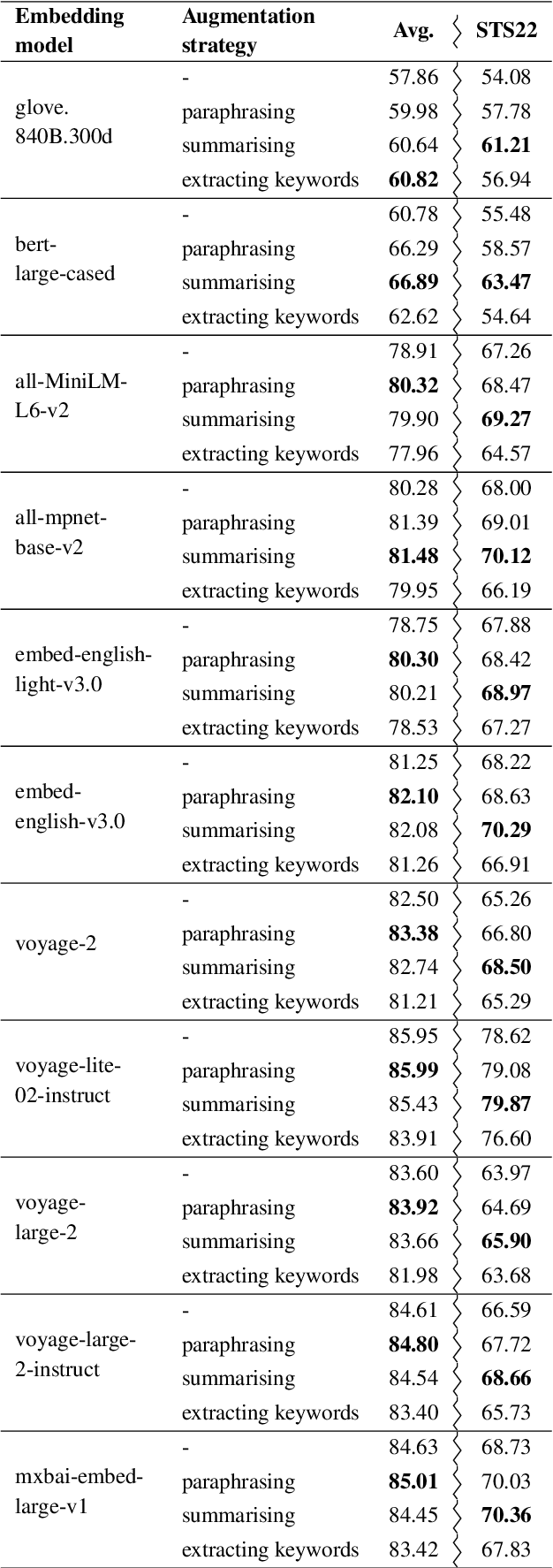
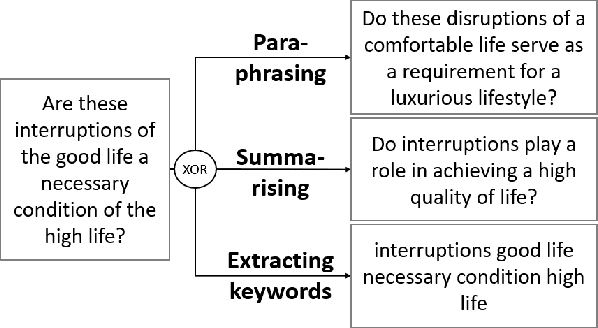
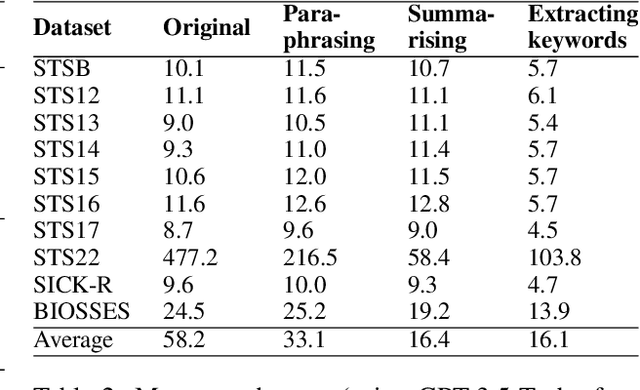
We propose an approach to enhance sentence embeddings by applying generative text models for data augmentation at inference time. Unlike conventional data augmentation that utilises synthetic training data, our approach does not require access to model parameters or the computational resources typically required for fine-tuning state-of-the-art models. Generatively Augmented Sentence Encoding uses diverse linguistic synthetic variants of input texts generated by paraphrasing, summarising, or extracting keywords, followed by pooling the original and synthetic embeddings. Experimental results on the Massive Text Embedding Benchmark for Semantic Textual Similarity (STS) demonstrate performance improvements across a range of embedding models using different generative models for augmentation. We find that generative augmentation leads to larger performance improvements for embedding models with lower baseline performance. These findings suggest that integrating generative augmentation at inference time adds semantic diversity and can enhance the robustness and generalizability of sentence embeddings for embedding models. Our results show that the degree to which generative augmentation can improve STS performance depends not only on the embedding model but also on the dataset. From a broader perspective, the approach allows trading training for inference compute.