 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSociotechnical Effects of Machine Translation
Mar 26, 2025
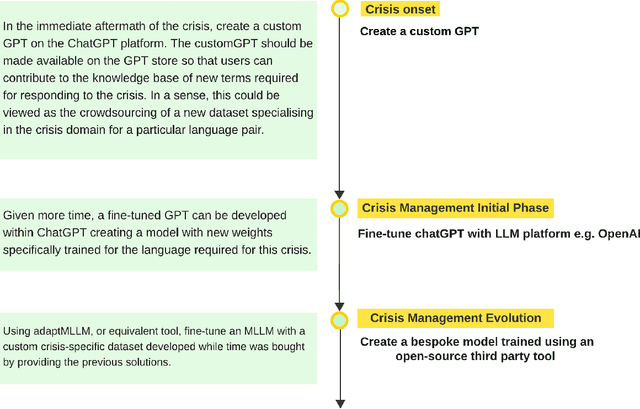
While the previous chapters have shown how machine translation (MT) can be useful, in this chapter we discuss some of the side-effects and risks that are associated, and how they might be mitigated. With the move to neural MT and approaches using Large Language Models (LLMs), there is an associated impact on climate change, as the models built by multinational corporations are massive. They are hugely expensive to train, consume large amounts of electricity, and output huge volumes of kgCO2 to boot. However, smaller models which still perform to a high level of quality can be built with much lower carbon footprints, and tuning pre-trained models saves on the requirement to train from scratch. We also discuss the possible detrimental effects of MT on translators and other users. The topics of copyright and ownership of data are discussed, as well as ethical considerations on data and MT use. Finally, we show how if done properly, using MT in crisis scenarios can save lives, and we provide a method of how this might be done.
Leveraging LLMs for MT in Crisis Scenarios: a blueprint for low-resource languages
Oct 31, 2024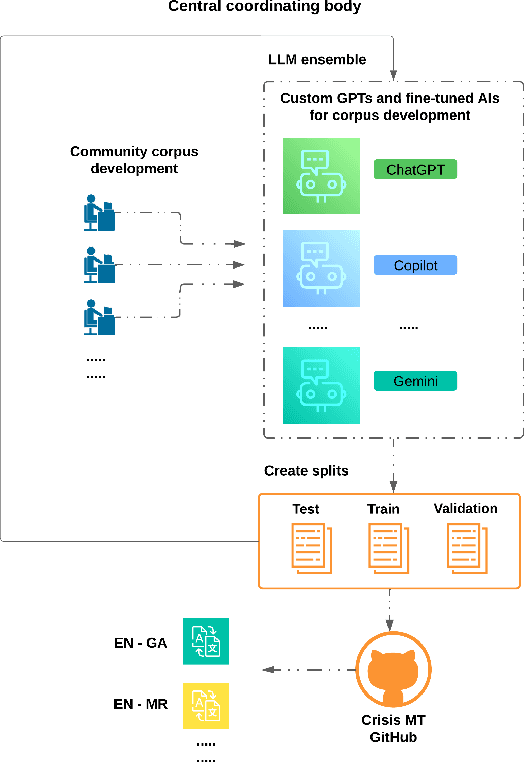

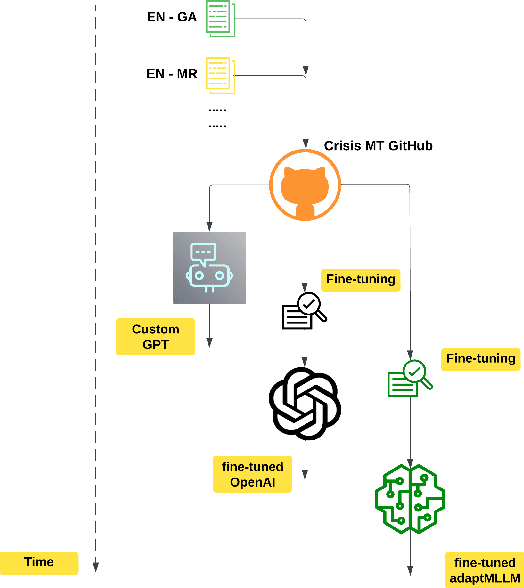

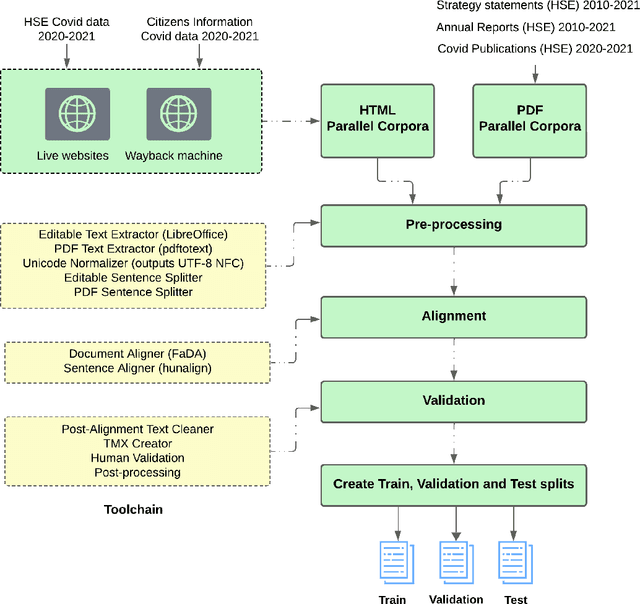
In an evolving landscape of crisis communication, the need for robust and adaptable Machine Translation (MT) systems is more pressing than ever, particularly for low-resource languages. This study presents a comprehensive exploration of leveraging Large Language Models (LLMs) and Multilingual LLMs (MLLMs) to enhance MT capabilities in such scenarios. By focusing on the unique challenges posed by crisis situations where speed, accuracy, and the ability to handle a wide range of languages are paramount, this research outlines a novel approach that combines the cutting-edge capabilities of LLMs with fine-tuning techniques and community-driven corpus development strategies. At the core of this study is the development and empirical evaluation of MT systems tailored for two low-resource language pairs, illustrating the process from initial model selection and fine-tuning through to deployment. Bespoke systems are developed and modelled on the recent Covid-19 pandemic. The research highlights the importance of community involvement in creating highly specialised, crisis-specific datasets and compares custom GPTs with NLLB-adapted MLLM models. It identifies fine-tuned MLLM models as offering superior performance compared with their LLM counterparts. A scalable and replicable model for rapid MT system development in crisis scenarios is outlined. Our approach enhances the field of humanitarian technology by offering a blueprint for developing multilingual communication systems during emergencies.
Neural Architecture Search using Particle Swarm and Ant Colony Optimization
Mar 06, 2024Neural network models have a number of hyperparameters that must be chosen along with their architecture. This can be a heavy burden on a novice user, choosing which architecture and what values to assign to parameters. In most cases, default hyperparameters and architectures are used. Significant improvements to model accuracy can be achieved through the evaluation of multiple architectures. A process known as Neural Architecture Search (NAS) may be applied to automatically evaluate a large number of such architectures. A system integrating open source tools for Neural Architecture Search (OpenNAS), in the classification of images, has been developed as part of this research. OpenNAS takes any dataset of grayscale, or RBG images, and generates Convolutional Neural Network (CNN) architectures based on a range of metaheuristics using either an AutoKeras, a transfer learning or a Swarm Intelligence (SI) approach. Particle Swarm Optimization (PSO) and Ant Colony Optimization (ACO) are used as the SI algorithms. Furthermore, models developed through such metaheuristics may be combined using stacking ensembles. In the context of this paper, we focus on training and optimizing CNNs using the Swarm Intelligence (SI) components of OpenNAS. Two major types of SI algorithms, namely PSO and ACO, are compared to see which is more effective in generating higher model accuracies. It is shown, with our experimental design, that the PSO algorithm performs better than ACO. The performance improvement of PSO is most notable with a more complex dataset. As a baseline, the performance of fine-tuned pre-trained models is also evaluated.
Design of an Open-Source Architecture for Neural Machine Translation
Mar 06, 2024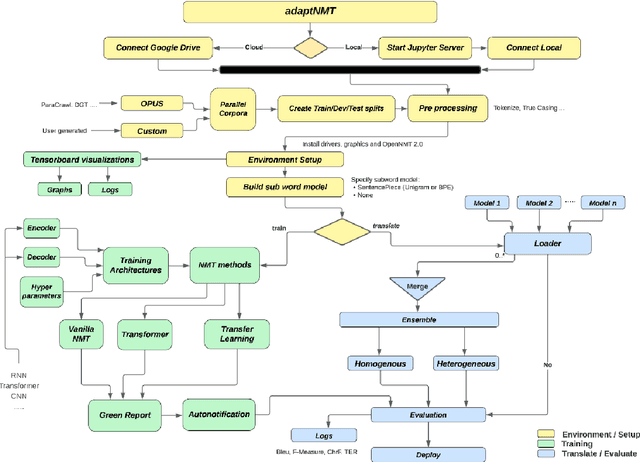
adaptNMT is an open-source application that offers a streamlined approach to the development and deployment of Recurrent Neural Networks and Transformer models. This application is built upon the widely-adopted OpenNMT ecosystem, and is particularly useful for new entrants to the field, as it simplifies the setup of the development environment and creation of train, validation, and test splits. The application offers a graphing feature that illustrates the progress of model training, and employs SentencePiece for creating subword segmentation models. Furthermore, the application provides an intuitive user interface that facilitates hyperparameter customization. Notably, a single-click model development approach has been implemented, and models developed by adaptNMT can be evaluated using a range of metrics. To encourage eco-friendly research, adaptNMT incorporates a green report that flags the power consumption and kgCO${_2}$ emissions generated during model development. The application is freely available.
* arXiv admin note: substantial text overlap with arXiv:2403.02367
gaHealth: An English-Irish Bilingual Corpus of Health Data
Mar 06, 2024
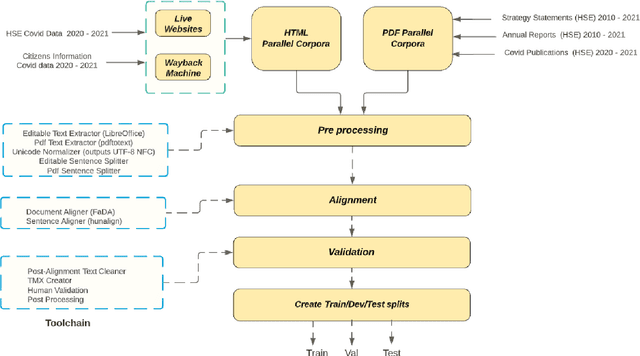
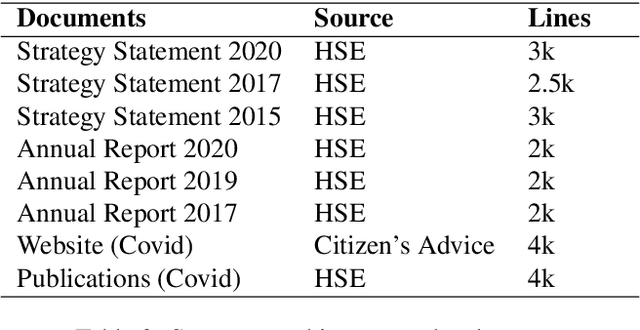
Machine Translation is a mature technology for many high-resource language pairs. However in the context of low-resource languages, there is a paucity of parallel data datasets available for developing translation models. Furthermore, the development of datasets for low-resource languages often focuses on simply creating the largest possible dataset for generic translation. The benefits and development of smaller in-domain datasets can easily be overlooked. To assess the merits of using in-domain data, a dataset for the specific domain of health was developed for the low-resource English to Irish language pair. Our study outlines the process used in developing the corpus and empirically demonstrates the benefits of using an in-domain dataset for the health domain. In the context of translating health-related data, models developed using the gaHealth corpus demonstrated a maximum BLEU score improvement of 22.2 points (40%) when compared with top performing models from the LoResMT2021 Shared Task. Furthermore, we define linguistic guidelines for developing gaHealth, the first bilingual corpus of health data for the Irish language, which we hope will be of use to other creators of low-resource data sets. gaHealth is now freely available online and is ready to be explored for further research.
* arXiv admin note: text overlap with arXiv:2403.02367
adaptNMT: an open-source, language-agnostic development environment for Neural Machine Translation
Mar 04, 2024adaptNMT streamlines all processes involved in the development and deployment of RNN and Transformer neural translation models. As an open-source application, it is designed for both technical and non-technical users who work in the field of machine translation. Built upon the widely-adopted OpenNMT ecosystem, the application is particularly useful for new entrants to the field since the setup of the development environment and creation of train, validation and test splits is greatly simplified. Graphing, embedded within the application, illustrates the progress of model training, and SentencePiece is used for creating subword segmentation models. Hyperparameter customization is facilitated through an intuitive user interface, and a single-click model development approach has been implemented. Models developed by adaptNMT can be evaluated using a range of metrics, and deployed as a translation service within the application. To support eco-friendly research in the NLP space, a green report also flags the power consumption and kgCO$_{2}$ emissions generated during model development. The application is freely available.
adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds
Mar 04, 2024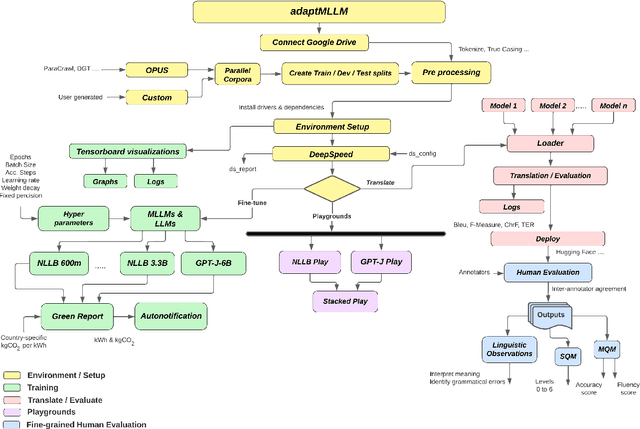

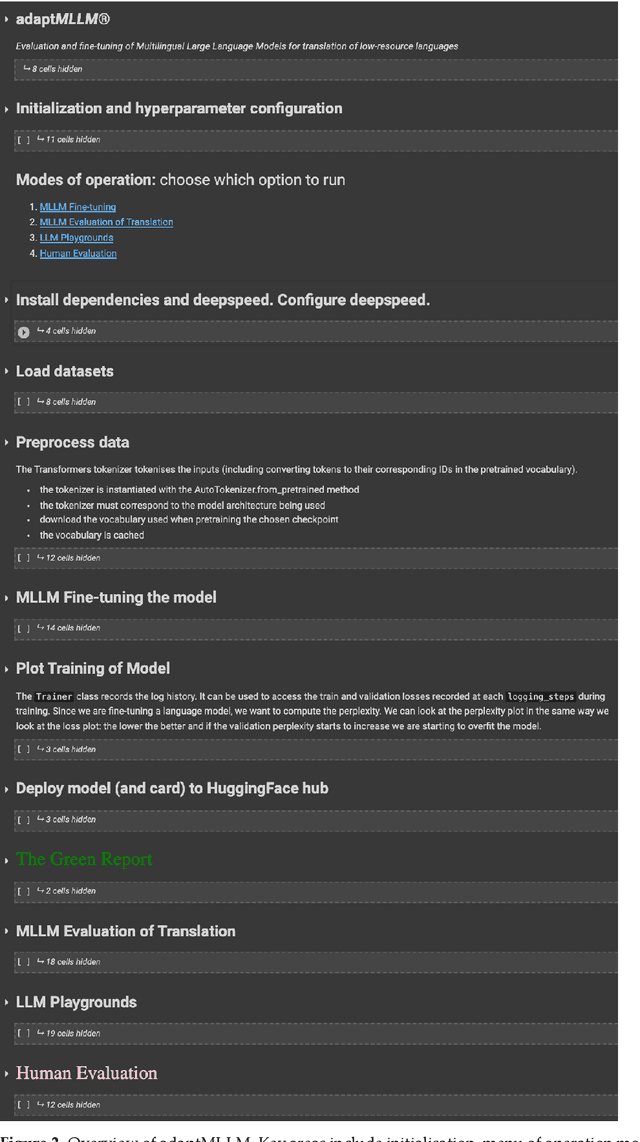
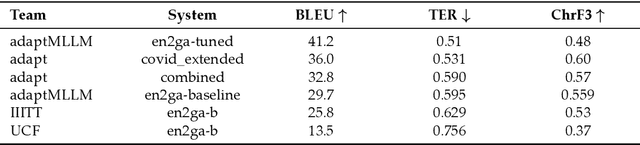
The advent of Multilingual Language Models (MLLMs) and Large Language Models has spawned innovation in many areas of natural language processing. Despite the exciting potential of this technology, its impact on developing high-quality Machine Translation (MT) outputs for low-resource languages remains relatively under-explored. Furthermore, an open-source application, dedicated to both fine-tuning MLLMs and managing the complete MT workflow for low-resources languages, remains unavailable. We aim to address these imbalances through the development of adaptMLLM, which streamlines all processes involved in the fine-tuning of MLLMs for MT. This open-source application is tailored for developers, translators, and users who are engaged in MT. An intuitive interface allows for easy customisation of hyperparameters, and the application offers a range of metrics for model evaluation and the capability to deploy models as a translation service directly within the application. As a multilingual tool, we used adaptMLLM to fine-tune models for two low-resource language pairs: English to Irish (EN$\leftrightarrow$GA) and English to Marathi (EN$\leftrightarrow$MR). Compared with baselines from the LoResMT2021 Shared Task, the adaptMLLM system demonstrated significant improvements. In the EN$\rightarrow$GA direction, an improvement of 5.2 BLEU points was observed and an increase of 40.5 BLEU points was recorded in the GA$\rightarrow$EN direction. Significant improvements in the translation performance of the EN$\leftrightarrow$MR pair were also observed notably in the MR$\rightarrow$EN direction with an increase of 21.3 BLEU points. Finally, a fine-grained human evaluation of the MLLM output on the EN$\rightarrow$GA pair was conducted using the Multidimensional Quality Metrics and Scalar Quality Metrics error taxonomies. The application and models are freely available.
Transformers for Low-Resource Languages:Is Féidir Linn!
Mar 04, 2024The Transformer model is the state-of-the-art in Machine Translation. However, in general, neural translation models often under perform on language pairs with insufficient training data. As a consequence, relatively few experiments have been carried out using this architecture on low-resource language pairs. In this study, hyperparameter optimization of Transformer models in translating the low-resource English-Irish language pair is evaluated. We demonstrate that choosing appropriate parameters leads to considerable performance improvements. Most importantly, the correct choice of subword model is shown to be the biggest driver of translation performance. SentencePiece models using both unigram and BPE approaches were appraised. Variations on model architectures included modifying the number of layers, testing various regularisation techniques and evaluating the optimal number of heads for attention. A generic 55k DGT corpus and an in-domain 88k public admin corpus were used for evaluation. A Transformer optimized model demonstrated a BLEU score improvement of 7.8 points when compared with a baseline RNN model. Improvements were observed across a range of metrics, including TER, indicating a substantially reduced post editing effort for Transformer optimized models with 16k BPE subword models. Bench-marked against Google Translate, our translation engines demonstrated significant improvements. The question of whether or not Transformers can be used effectively in a low-resource setting of English-Irish translation has been addressed. Is f\'eidir linn - yes we can.
* 13 pages
Human Evaluation of English--Irish Transformer-Based NMT
Mar 04, 2024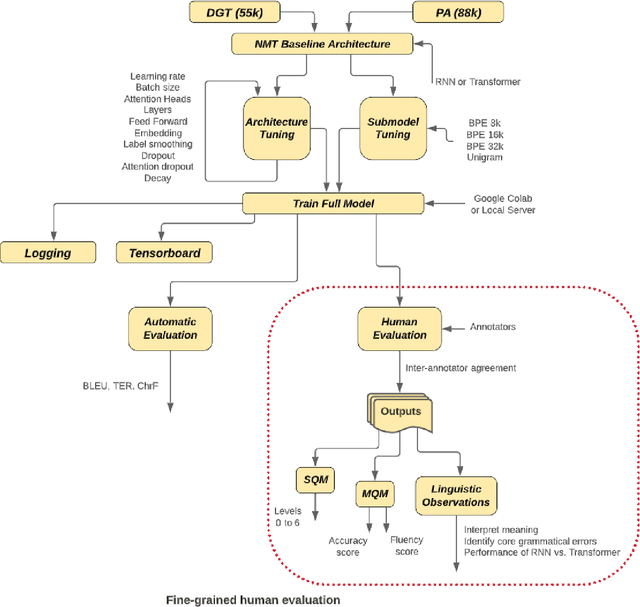


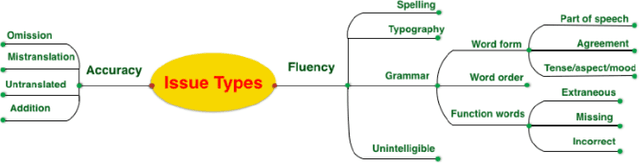
In this study, a human evaluation is carried out on how hyperparameter settings impact the quality of Transformer-based Neural Machine Translation (NMT) for the low-resourced English--Irish pair. SentencePiece models using both Byte Pair Encoding (BPE) and unigram approaches were appraised. Variations in model architectures included modifying the number of layers, evaluating the optimal number of heads for attention and testing various regularisation techniques. The greatest performance improvement was recorded for a Transformer-optimized model with a 16k BPE subword model. Compared with a baseline Recurrent Neural Network (RNN) model, a Transformer-optimized model demonstrated a BLEU score improvement of 7.8 points. When benchmarked against Google Translate, our translation engines demonstrated significant improvements. Furthermore, a quantitative fine-grained manual evaluation was conducted which compared the performance of machine translation systems. Using the Multidimensional Quality Metrics (MQM) error taxonomy, a human evaluation of the error types generated by an RNN-based system and a Transformer-based system was explored. Our findings show the best-performing Transformer system significantly reduces both accuracy and fluency errors when compared with an RNN-based model.
* arXiv admin note: text overlap with arXiv:2403.01985
Enhancing Neural Machine Translation of Low-Resource Languages: Corpus Development, Human Evaluation and Explainable AI Architectures
Mar 03, 2024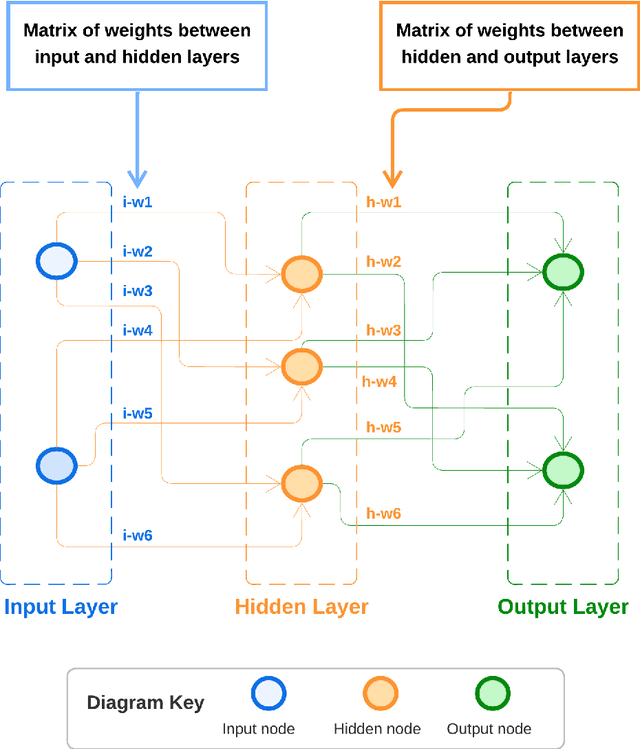
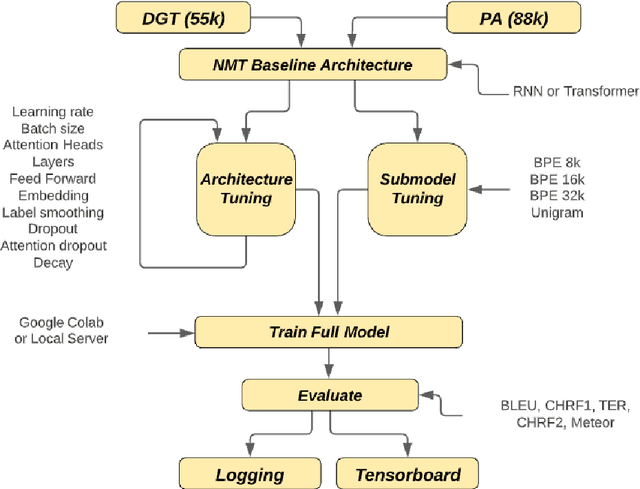
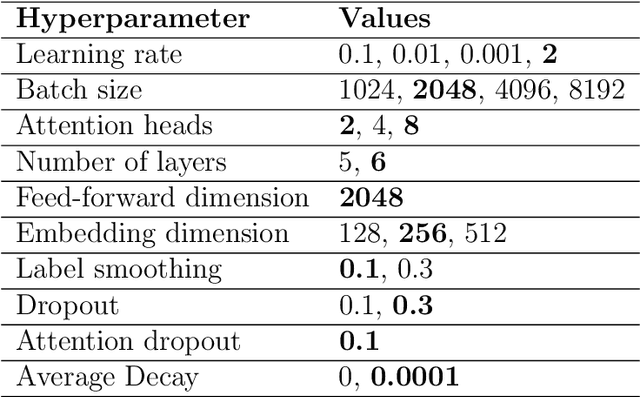
In the current machine translation (MT) landscape, the Transformer architecture stands out as the gold standard, especially for high-resource language pairs. This research delves into its efficacy for low-resource language pairs including both the English$\leftrightarrow$Irish and English$\leftrightarrow$Marathi language pairs. Notably, the study identifies the optimal hyperparameters and subword model type to significantly improve the translation quality of Transformer models for low-resource language pairs. The scarcity of parallel datasets for low-resource languages can hinder MT development. To address this, gaHealth was developed, the first bilingual corpus of health data for the Irish language. Focusing on the health domain, models developed using this in-domain dataset exhibited very significant improvements in BLEU score when compared with models from the LoResMT2021 Shared Task. A subsequent human evaluation using the multidimensional quality metrics error taxonomy showcased the superior performance of the Transformer system in reducing both accuracy and fluency errors compared to an RNN-based counterpart. Furthermore, this thesis introduces adaptNMT and adaptMLLM, two open-source applications streamlined for the development, fine-tuning, and deployment of neural machine translation models. These tools considerably simplify the setup and evaluation process, making MT more accessible to both developers and translators. Notably, adaptNMT, grounded in the OpenNMT ecosystem, promotes eco-friendly natural language processing research by highlighting the environmental footprint of model development. Fine-tuning of MLLMs by adaptMLLM demonstrated advancements in translation performance for two low-resource language pairs: English$\leftrightarrow$Irish and English$\leftrightarrow$Marathi, compared to baselines from the LoResMT2021 Shared Task.