 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgegaHealth: An English-Irish Bilingual Corpus of Health Data
Paper and Code

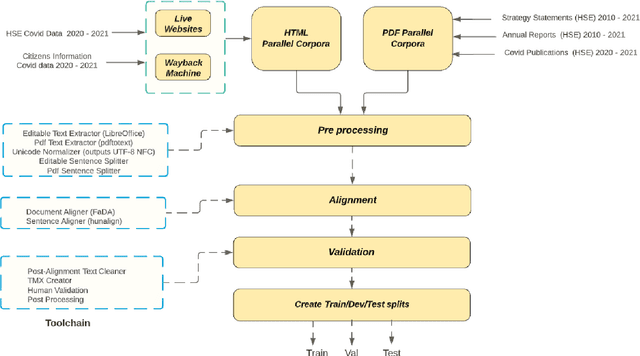
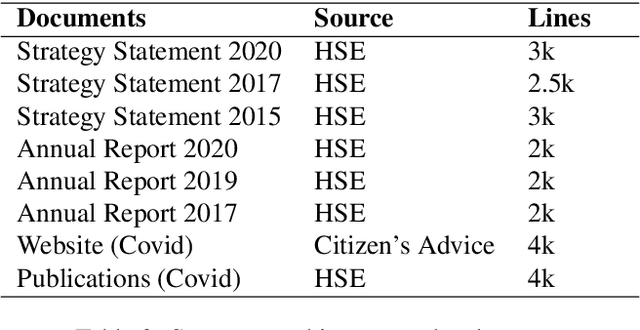
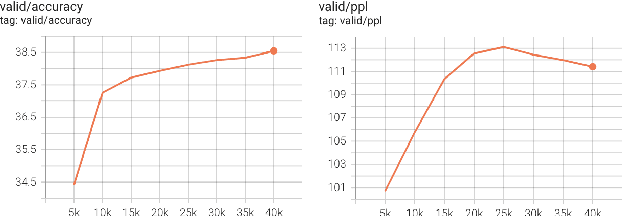
Machine Translation is a mature technology for many high-resource language pairs. However in the context of low-resource languages, there is a paucity of parallel data datasets available for developing translation models. Furthermore, the development of datasets for low-resource languages often focuses on simply creating the largest possible dataset for generic translation. The benefits and development of smaller in-domain datasets can easily be overlooked. To assess the merits of using in-domain data, a dataset for the specific domain of health was developed for the low-resource English to Irish language pair. Our study outlines the process used in developing the corpus and empirically demonstrates the benefits of using an in-domain dataset for the health domain. In the context of translating health-related data, models developed using the gaHealth corpus demonstrated a maximum BLEU score improvement of 22.2 points (40%) when compared with top performing models from the LoResMT2021 Shared Task. Furthermore, we define linguistic guidelines for developing gaHealth, the first bilingual corpus of health data for the Irish language, which we hope will be of use to other creators of low-resource data sets. gaHealth is now freely available online and is ready to be explored for further research.