 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs for MT in Crisis Scenarios: a blueprint for low-resource languages
Paper and Code
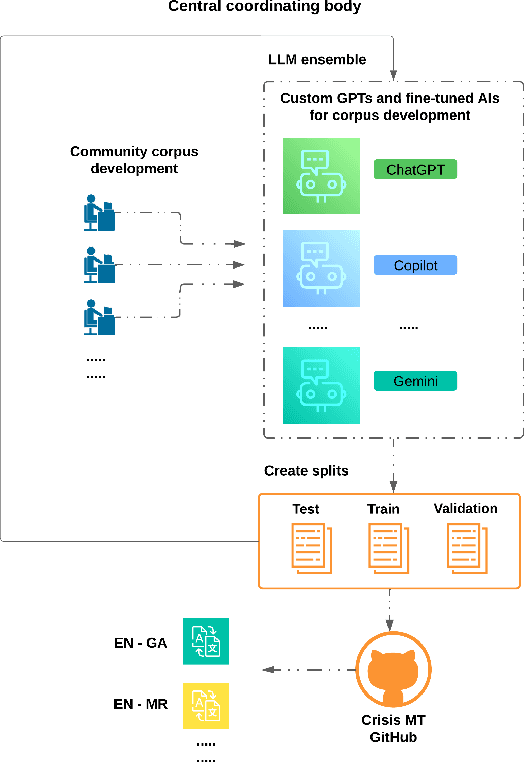

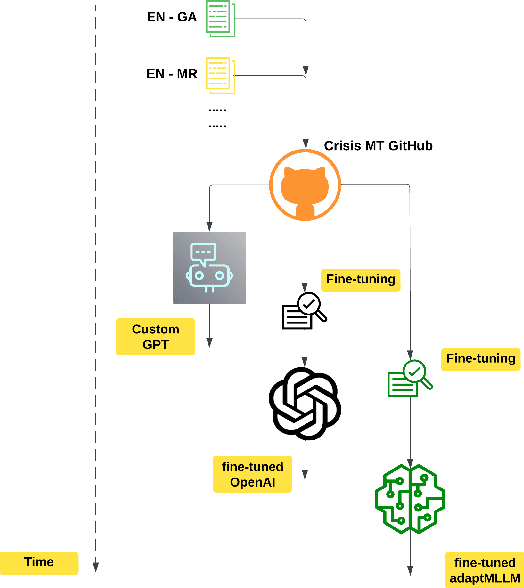

In an evolving landscape of crisis communication, the need for robust and adaptable Machine Translation (MT) systems is more pressing than ever, particularly for low-resource languages. This study presents a comprehensive exploration of leveraging Large Language Models (LLMs) and Multilingual LLMs (MLLMs) to enhance MT capabilities in such scenarios. By focusing on the unique challenges posed by crisis situations where speed, accuracy, and the ability to handle a wide range of languages are paramount, this research outlines a novel approach that combines the cutting-edge capabilities of LLMs with fine-tuning techniques and community-driven corpus development strategies. At the core of this study is the development and empirical evaluation of MT systems tailored for two low-resource language pairs, illustrating the process from initial model selection and fine-tuning through to deployment. Bespoke systems are developed and modelled on the recent Covid-19 pandemic. The research highlights the importance of community involvement in creating highly specialised, crisis-specific datasets and compares custom GPTs with NLLB-adapted MLLM models. It identifies fine-tuned MLLM models as offering superior performance compared with their LLM counterparts. A scalable and replicable model for rapid MT system development in crisis scenarios is outlined. Our approach enhances the field of humanitarian technology by offering a blueprint for developing multilingual communication systems during emergencies.