 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitfed learning without client-side synchronization: Analyzing client-side split network portion size to overall performance
Sep 19, 2021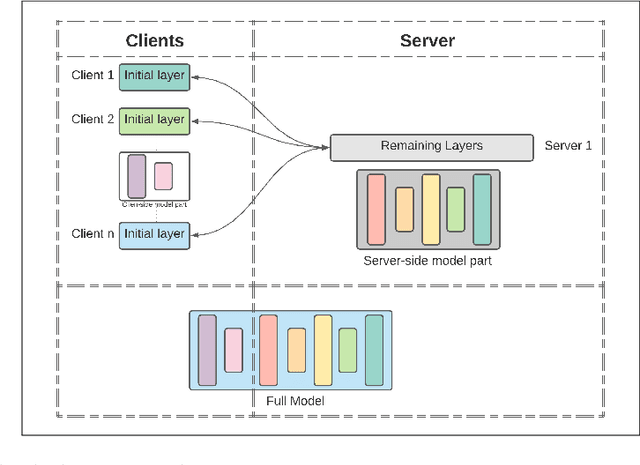


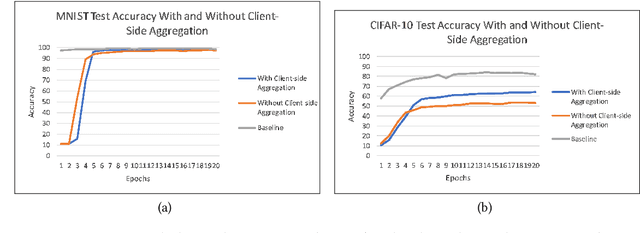
Federated Learning (FL), Split Learning (SL), and SplitFed Learning (SFL) are three recent developments in distributed machine learning that are gaining attention due to their ability to preserve the privacy of raw data. Thus, they are widely applicable in various domains where data is sensitive, such as large-scale medical image classification, internet-of-medical-things, and cross-organization phishing email detection. SFL is developed on the confluence point of FL and SL. It brings the best of FL and SL by providing parallel client-side machine learning model updates from the FL paradigm and a higher level of model privacy (while training) by splitting the model between the clients and server coming from SL. However, SFL has communication and computation overhead at the client-side due to the requirement of client-side model synchronization. For the resource-constrained client-side, removal of such requirements is required to gain efficiency in the learning. In this regard, this paper studies SFL without client-side model synchronization. The resulting architecture is known as Multi-head Split Learning. Our empirical studies considering the ResNet18 model on MNIST data under IID data distribution among distributed clients find that Multi-head Split Learning is feasible. Its performance is comparable to the SFL. Moreover, SFL provides only 1%-2% better accuracy than Multi-head Split Learning on the MNIST test set. To further strengthen our results, we study the Multi-head Split Learning with various client-side model portions and its impact on the overall performance. To this end, our results find a minimal impact on the overall performance of the model.