Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMH-MoE: Multi-Head Mixture-of-Experts
Paper and Code
Nov 26, 2024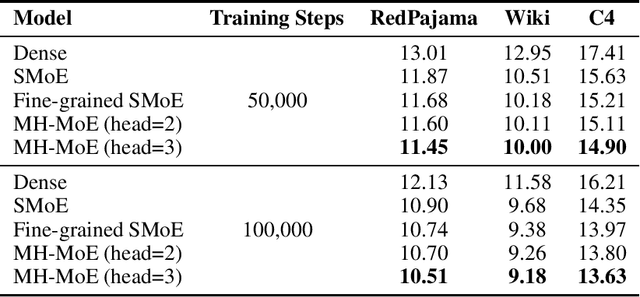
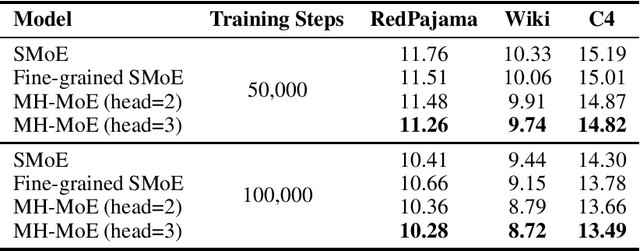
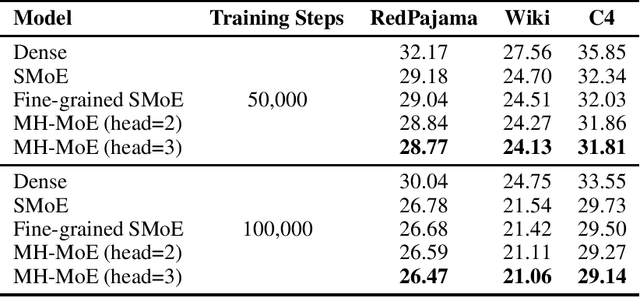

Multi-Head Mixture-of-Experts (MH-MoE) demonstrates superior performance by using the multi-head mechanism to collectively attend to information from various representation spaces within different experts. In this paper, we present a novel implementation of MH-MoE that maintains both FLOPs and parameter parity with sparse Mixture of Experts models. Experimental results on language models show that the new implementation yields quality improvements over both vanilla MoE and fine-grained MoE models. Additionally, our experiments demonstrate that MH-MoE is compatible with 1-bit Large Language Models (LLMs) such as BitNet.
* 7 pages, 0 figures
View paper on