 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition-aware Guided Point Cloud Completion with CLIP Model
Dec 11, 2024
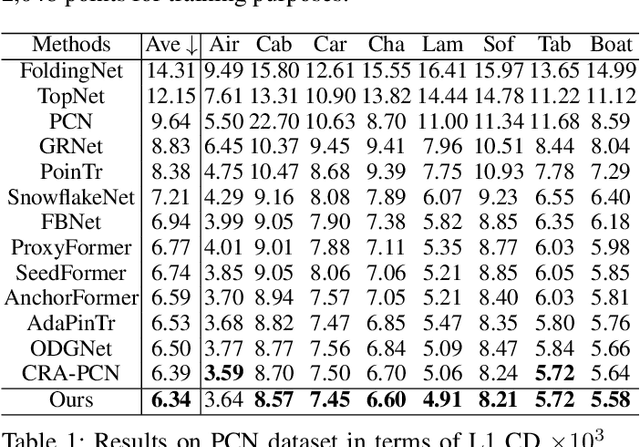


Point cloud completion aims to recover partial geometric and topological shapes caused by equipment defects or limited viewpoints. Current methods either solely rely on the 3D coordinates of the point cloud to complete it or incorporate additional images with well-calibrated intrinsic parameters to guide the geometric estimation of the missing parts. Although these methods have achieved excellent performance by directly predicting the location of complete points, the extracted features lack fine-grained information regarding the location of the missing area. To address this issue, we propose a rapid and efficient method to expand an unimodal framework into a multimodal framework. This approach incorporates a position-aware module designed to enhance the spatial information of the missing parts through a weighted map learning mechanism. In addition, we establish a Point-Text-Image triplet corpus PCI-TI and MVP-TI based on the existing unimodal point cloud completion dataset and use the pre-trained vision-language model CLIP to provide richer detail information for 3D shapes, thereby enhancing performance. Extensive quantitative and qualitative experiments demonstrate that our method outperforms state-of-the-art point cloud completion methods.