 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational autoencoders stabilise TCN performance when classifying weakly labelled bioacoustics data
Oct 22, 2024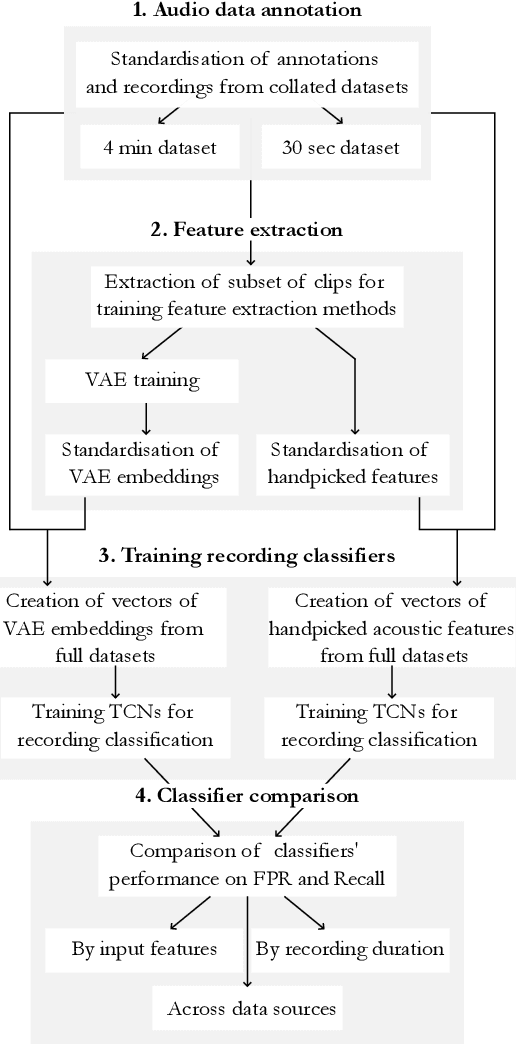
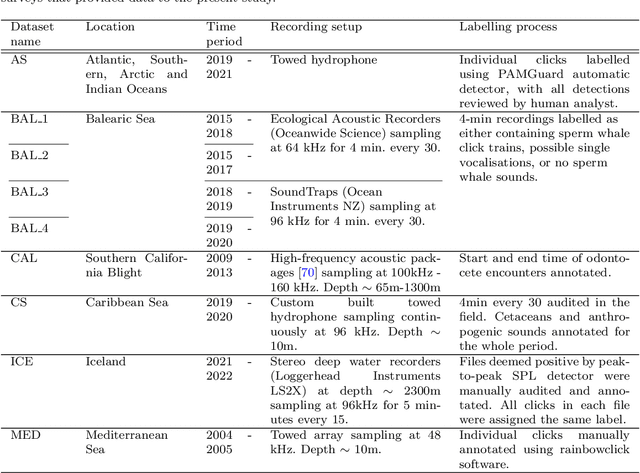
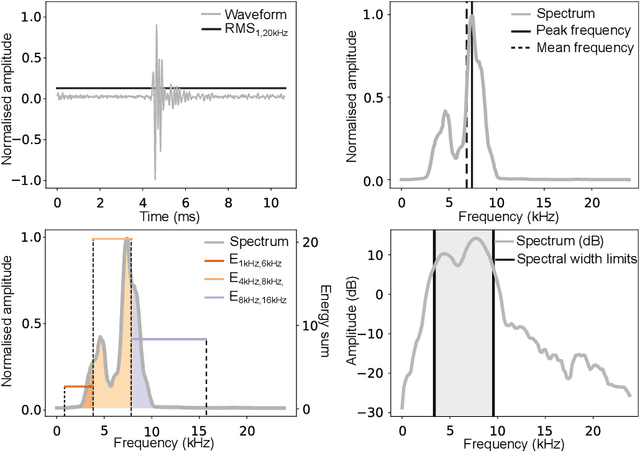

Passive acoustic monitoring (PAM) data is often weakly labelled, audited at the scale of detection presence or absence on timescales of minutes to hours. Moreover, this data exhibits great variability from one deployment to the next, due to differences in ambient noise and the signals across sources and geographies. This study proposes a two-step solution to leverage weakly annotated data for training Deep Learning (DL) detection models. Our case study involves binary classification of the presence/absence of sperm whale (\textit{Physeter macrocephalus}) click trains in 4-minute-long recordings from a dataset comprising diverse sources and deployment conditions to maximise generalisability. We tested methods for extracting acoustic features from lengthy audio segments and integrated Temporal Convolutional Networks (TCNs) trained on the extracted features for sequence classification. For feature extraction, we introduced a new approach using Variational AutoEncoders (VAEs) to extract information from both waveforms and spectrograms, which eliminates the necessity for manual threshold setting or time-consuming strong labelling. For classification, TCNs were trained separately on sequences of either VAE embeddings or handpicked acoustic features extracted from the waveform and spectrogram representations using classical methods, to compare the efficacy of the two approaches. The TCN demonstrated robust classification capabilities on a validation set, achieving accuracies exceeding 85\% when applied to 4-minute acoustic recordings. Notably, TCNs trained on handpicked acoustic features exhibited greater variability in performance across recordings from diverse deployment conditions, whereas those trained on VAEs showed a more consistent performance, highlighting the robust transferability of VAEs for feature extraction across different deployment conditions.
How likely is a random graph shift-enabled?
Aug 28, 2021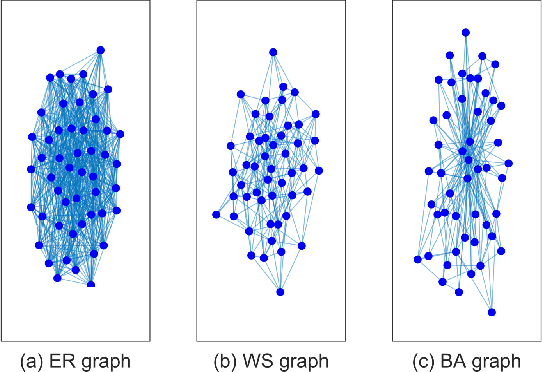
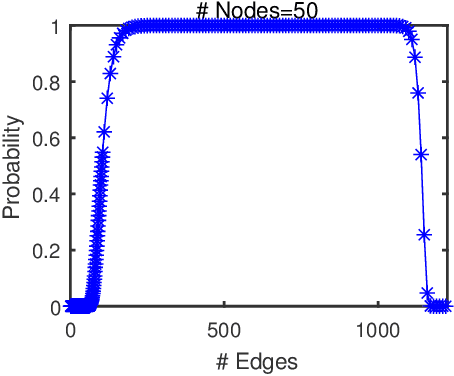
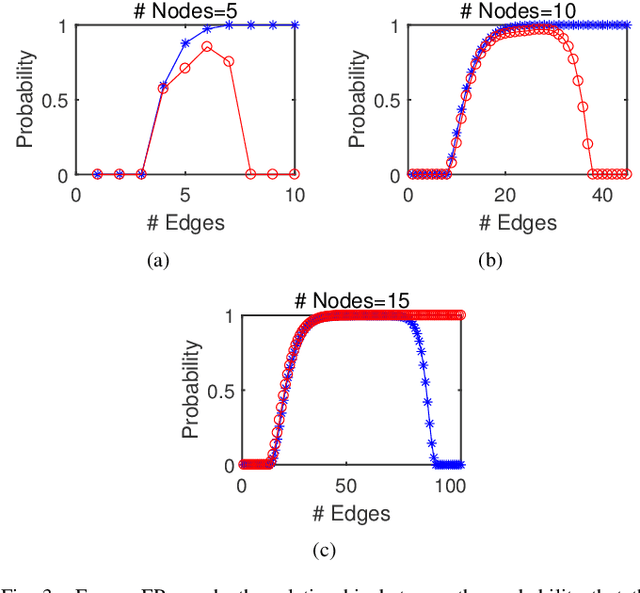
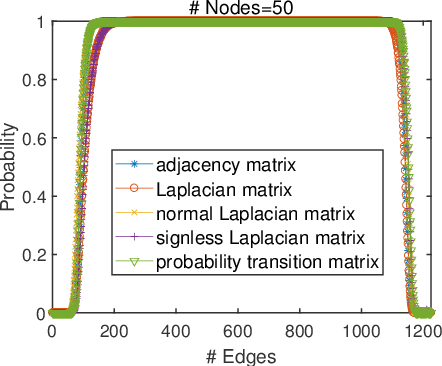
The shift-enabled property of an underlying graph is essential in designing distributed filters. This article discusses when a random graph is shift-enabled. In particular, popular graph models ER, WS, BA random graph are used, weighted and unweighted, as well as signed graphs. Our results show that the considered unweighted connected random graphs are shift-enabled with high probability when the number of edges is moderately high. However, very dense graphs, as well as fully connected graphs, are not shift-enabled. Interestingly, this behaviour is not observed for weighted connected graphs, which are always shift-enabled unless the number of edges in the graph is very low.
Robust Deep Graph Based Learning for Binary Classification
Dec 06, 2019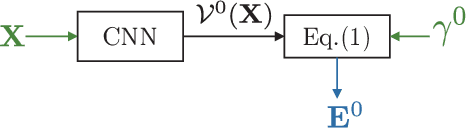

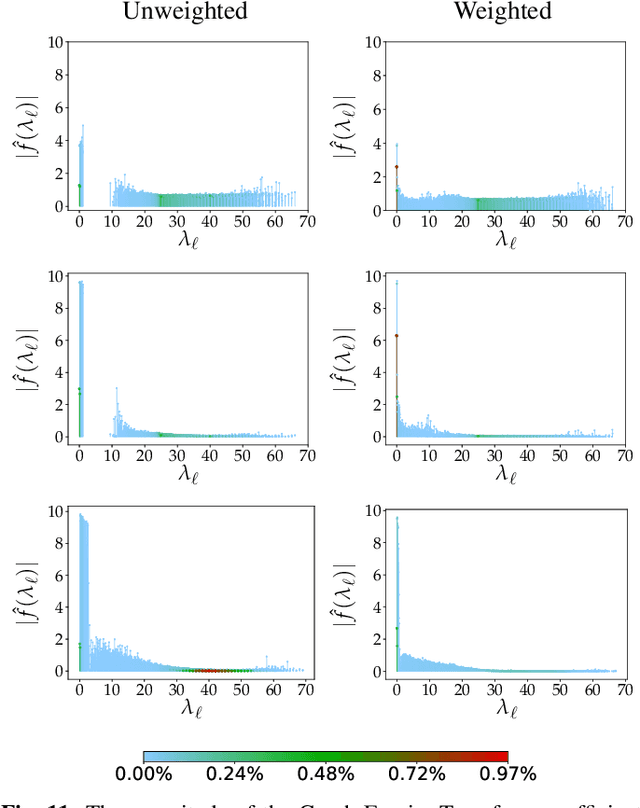
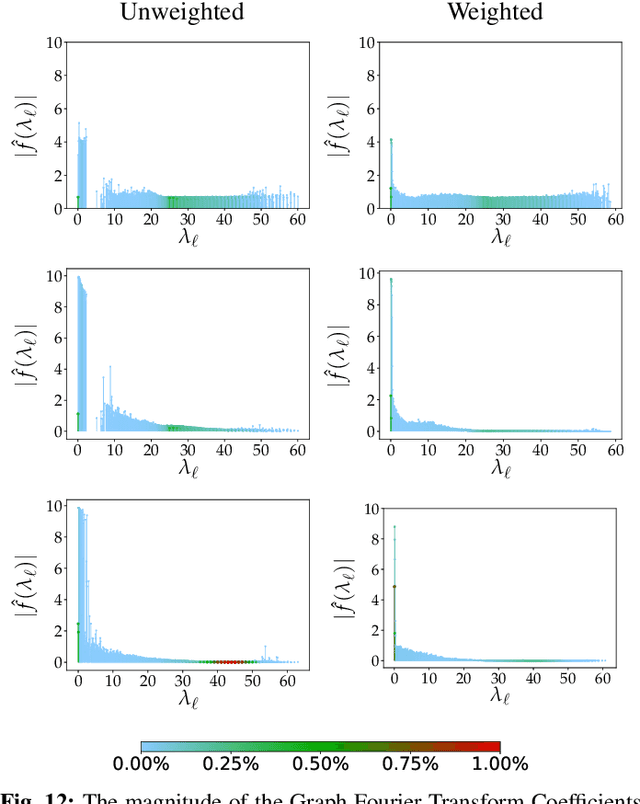
Convolutional neural network (CNN)-based feature learning has become state of the art, since given sufficient training data, CNN can significantly outperform traditional methods for various classification tasks. However, feature learning becomes more difficult if some training labels are noisy. With traditional regularization techniques, CNN often overfits to the noisy training labels, resulting in sub-par classification performance. In this paper, we propose a robust binary classifier, based on CNNs, to learn deep metric functions, which are then used to construct an optimal underlying graph structure used to clean noisy labels via graph Laplacian regularization (GLR). GLR is posed as a convex maximum a posteriori (MAP) problem solved via convex quadratic programming (QP). To penalize samples around the decision boundary, we propose two regularized loss functions for semi-supervised learning. The binary classification experiments on three datasets, varying in number and type of features, demonstrate that given a noisy training dataset, our proposed networks outperform several state-of-the-art classifiers, including label-noise robust support vector machine, CNNs with three different robust loss functions, model-based GLR, and dynamic graph CNN classifiers.