 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Revised Generative Evaluation of Visual Dialogue
Paper and Code

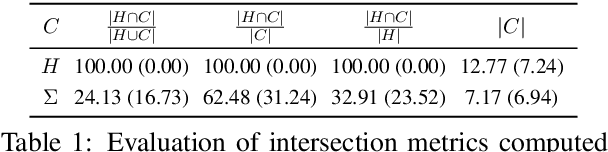
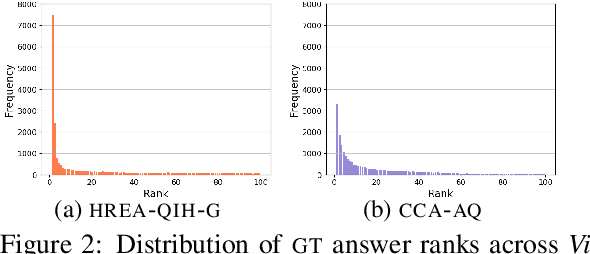
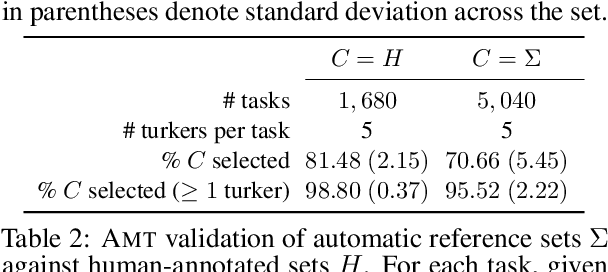
Evaluating Visual Dialogue, the task of answering a sequence of questions relating to a visual input, remains an open research challenge. The current evaluation scheme of the VisDial dataset computes the ranks of ground-truth answers in predefined candidate sets, which Massiceti et al. (2018) show can be susceptible to the exploitation of dataset biases. This scheme also does little to account for the different ways of expressing the same answer--an aspect of language that has been well studied in NLP. We propose a revised evaluation scheme for the VisDial dataset leveraging metrics from the NLP literature to measure consensus between answers generated by the model and a set of relevant answers. We construct these relevant answer sets using a simple and effective semi-supervised method based on correlation, which allows us to automatically extend and scale sparse relevance annotations from humans to the entire dataset. We release these sets and code for the revised evaluation scheme as DenseVisDial, and intend them to be an improvement to the dataset in the face of its existing constraints and design choices.