 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards measuring fairness in AI: the Casual Conversations dataset
Paper and Code
Apr 06, 2021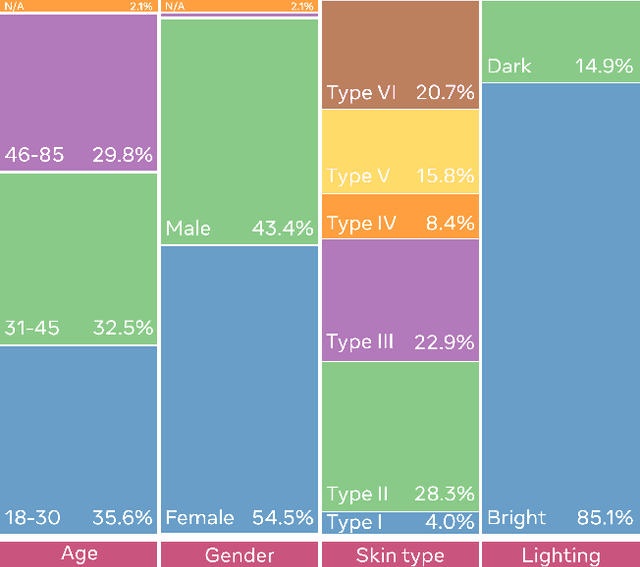



This paper introduces a novel dataset to help researchers evaluate their computer vision and audio models for accuracy across a diverse set of age, genders, apparent skin tones and ambient lighting conditions. Our dataset is composed of 3,011 subjects and contains over 45,000 videos, with an average of 15 videos per person. The videos were recorded in multiple U.S. states with a diverse set of adults in various age, gender and apparent skin tone groups. A key feature is that each subject agreed to participate for their likenesses to be used. Additionally, our age and gender annotations are provided by the subjects themselves. A group of trained annotators labeled the subjects' apparent skin tone using the Fitzpatrick skin type scale. Moreover, annotations for videos recorded in low ambient lighting are also provided. As an application to measure robustness of predictions across certain attributes, we provide a comprehensive study on the top five winners of the DeepFake Detection Challenge (DFDC). Experimental evaluation shows that the winning models are less performant on some specific groups of people, such as subjects with darker skin tones and thus may not generalize to all people. In addition, we also evaluate the state-of-the-art apparent age and gender classification methods. Our experiments provides a through analysis on these models in terms of fair treatment of people from various backgrounds.