 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Cellular Recurrent Network for Efficient Analysis of Time-Series Data with Spatial Information
Jan 12, 2021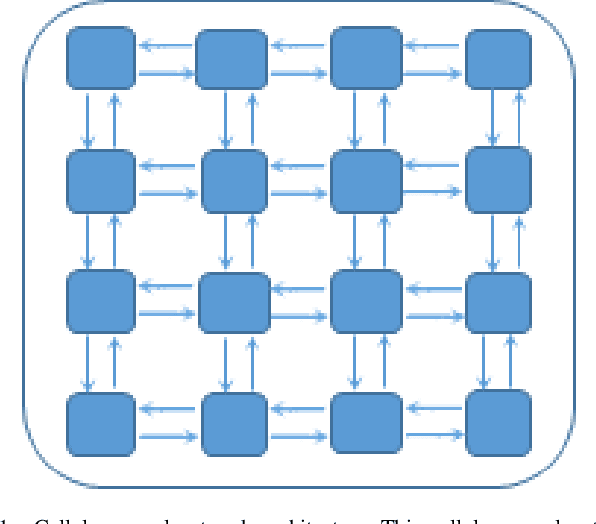
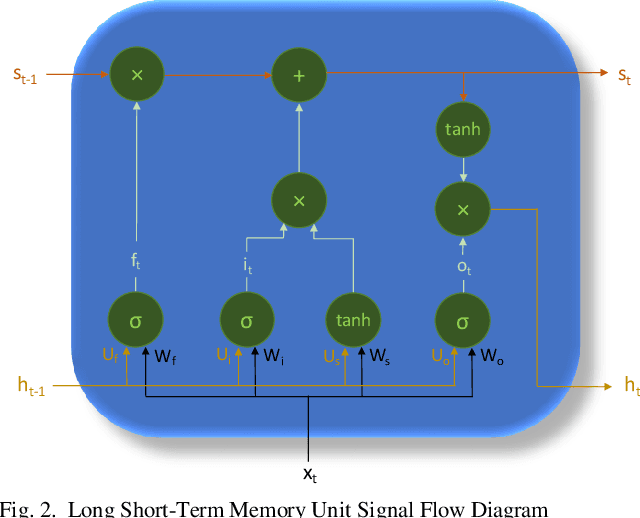
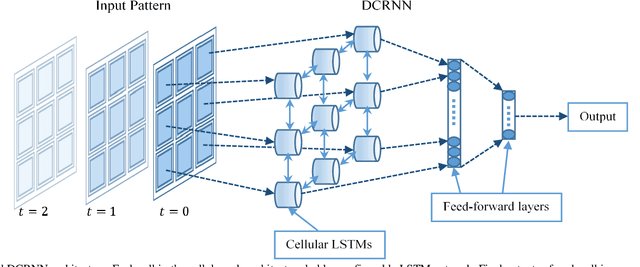
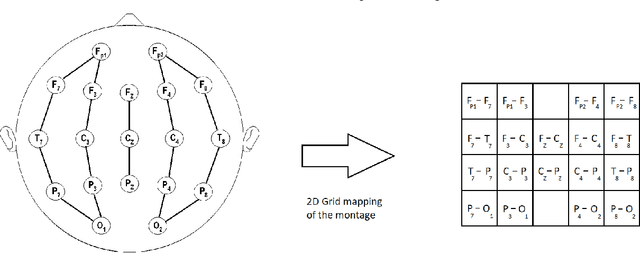
Efficient processing of large-scale time series data is an intricate problem in machine learning. Conventional sensor signal processing pipelines with hand engineered feature extraction often involve huge computational cost with high dimensional data. Deep recurrent neural networks have shown promise in automated feature learning for improved time-series processing. However, generic deep recurrent models grow in scale and depth with increased complexity of the data. This is particularly challenging in presence of high dimensional data with temporal and spatial characteristics. Consequently, this work proposes a novel deep cellular recurrent neural network (DCRNN) architecture to efficiently process complex multi-dimensional time series data with spatial information. The cellular recurrent architecture in the proposed model allows for location-aware synchronous processing of time series data from spatially distributed sensor signal sources. Extensive trainable parameter sharing due to cellularity in the proposed architecture ensures efficiency in the use of recurrent processing units with high-dimensional inputs. This study also investigates the versatility of the proposed DCRNN model for classification of multi-class time series data from different application domains. Consequently, the proposed DCRNN architecture is evaluated using two time-series datasets: a multichannel scalp EEG dataset for seizure detection, and a machine fault detection dataset obtained in-house. The results suggest that the proposed architecture achieves state-of-the-art performance while utilizing substantially less trainable parameters when compared to comparable methods in the literature.
Survey on Deep Neural Networks in Speech and Vision Systems
Aug 16, 2019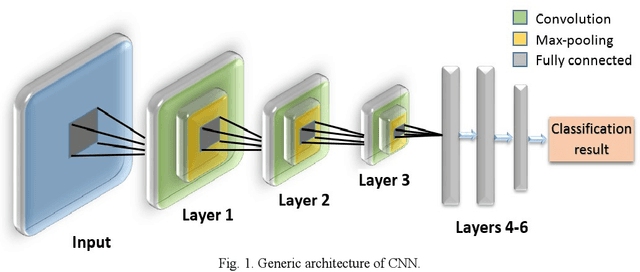
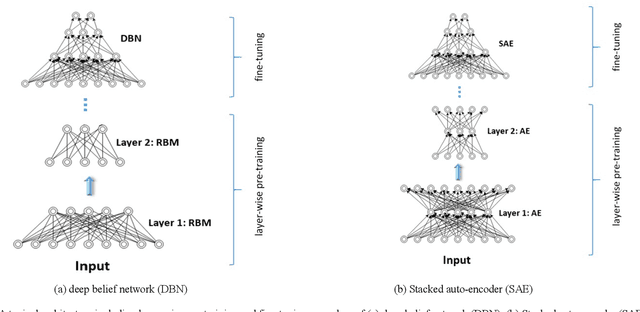
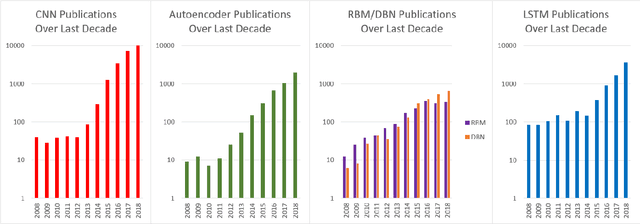
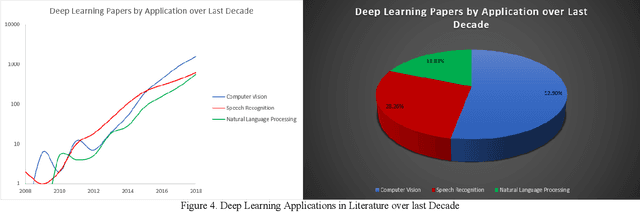
This survey presents a review of state-of-the-art deep neural network architectures, algorithms, and systems in vision and speech applications. Recent advances in deep artificial neural network algorithms and architectures have spurred rapid innovation and development of intelligent vision and speech systems. With availability of vast amounts of sensor data and cloud computing for processing and training of deep neural networks, and with increased sophistication in mobile and embedded technology, the next-generation intelligent systems are poised to revolutionize personal and commercial computing. This survey begins by providing background and evolution of some of the most successful deep learning models for intelligent vision and speech systems to date. An overview of large-scale industrial research and development efforts is provided to emphasize future trends and prospects of intelligent vision and speech systems. Robust and efficient intelligent systems demand low-latency and high fidelity in resource constrained hardware platforms such as mobile devices, robots, and automobiles. Therefore, this survey also provides a summary of key challenges and recent successes in running deep neural networks on hardware-restricted platforms, i.e. within limited memory, battery life, and processing capabilities. Finally, emerging applications of vision and speech across disciplines such as affective computing, intelligent transportation, and precision medicine are discussed. To our knowledge, this paper provides one of the most comprehensive surveys on the latest developments in intelligent vision and speech applications from the perspectives of both software and hardware systems. Many of these emerging technologies using deep neural networks show tremendous promise to revolutionize research and development for future vision and speech systems.