 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian regularization of empirical MDPs
Aug 03, 2022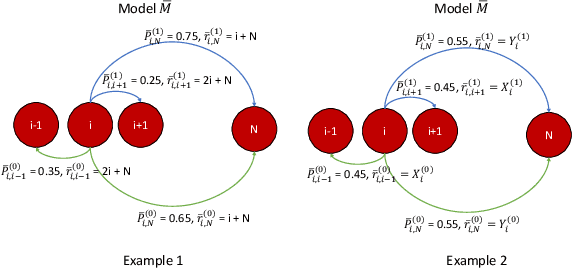
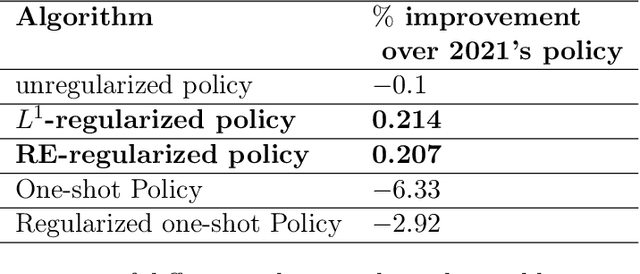
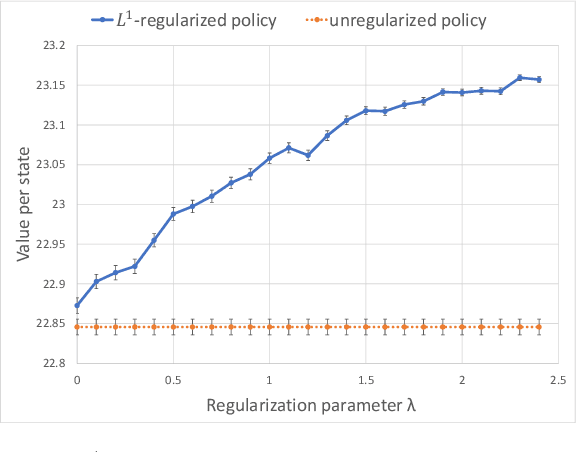
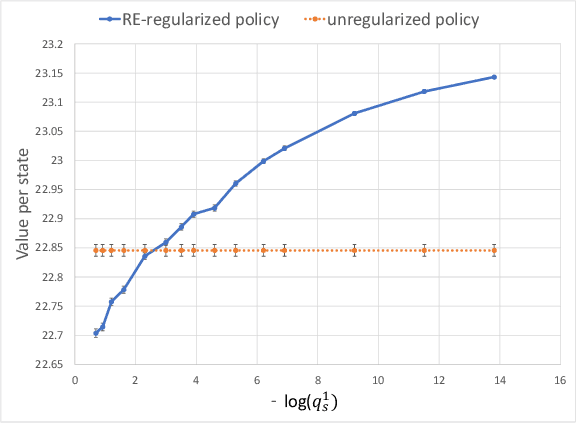
In most applications of model-based Markov decision processes, the parameters for the unknown underlying model are often estimated from the empirical data. Due to noise, the policy learnedfrom the estimated model is often far from the optimal policy of the underlying model. When applied to the environment of the underlying model, the learned policy results in suboptimal performance, thus calling for solutions with better generalization performance. In this work we take a Bayesian perspective and regularize the objective function of the Markov decision process with prior information in order to obtain more robust policies. Two approaches are proposed, one based on $L^1$ regularization and the other on relative entropic regularization. We evaluate our proposed algorithms on synthetic simulations and on real-world search logs of a large scale online shopping store. Our results demonstrate the robustness of regularized MDP policies against the noise present in the models.
Counterfactual Learning To Rank for Utility-Maximizing Query Autocompletion
Apr 22, 2022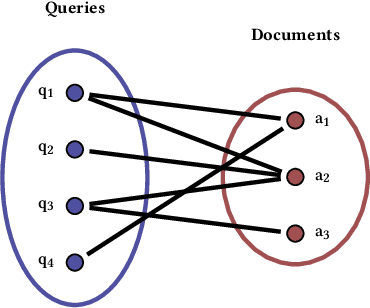

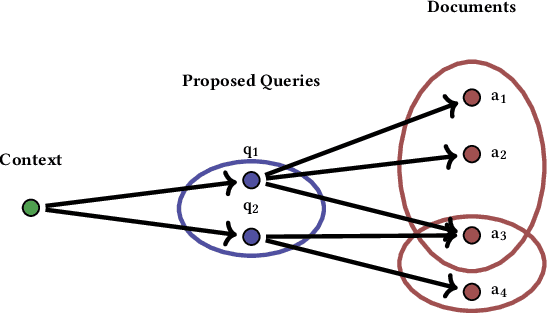
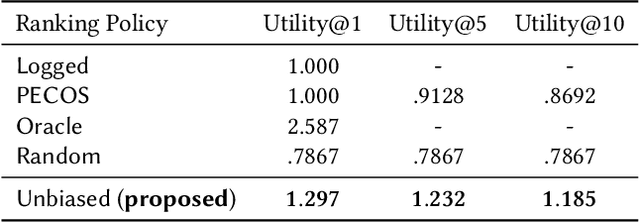
Conventional methods for query autocompletion aim to predict which completed query a user will select from a list. A shortcoming of this approach is that users often do not know which query will provide the best retrieval performance on the current information retrieval system, meaning that any query autocompletion methods trained to mimic user behavior can lead to suboptimal query suggestions. To overcome this limitation, we propose a new approach that explicitly optimizes the query suggestions for downstream retrieval performance. We formulate this as a problem of ranking a set of rankings, where each query suggestion is represented by the downstream item ranking it produces. We then present a learning method that ranks query suggestions by the quality of their item rankings. The algorithm is based on a counterfactual learning approach that is able to leverage feedback on the items (e.g., clicks, purchases) to evaluate query suggestions through an unbiased estimator, thus avoiding the assumption that users write or select optimal queries. We establish theoretical support for the proposed approach and provide learning-theoretic guarantees. We also present empirical results on publicly available datasets, and demonstrate real-world applicability using data from an online shopping store.
Session-Aware Query Auto-completion using Extreme Multi-label Ranking
Dec 09, 2020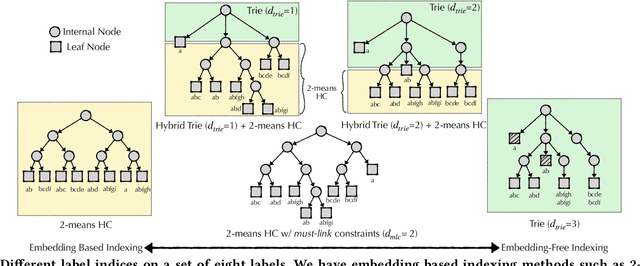
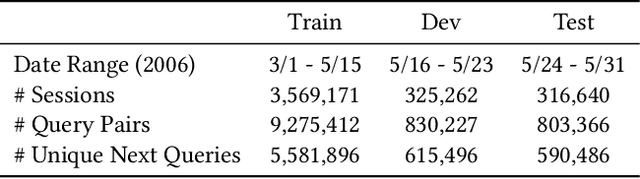
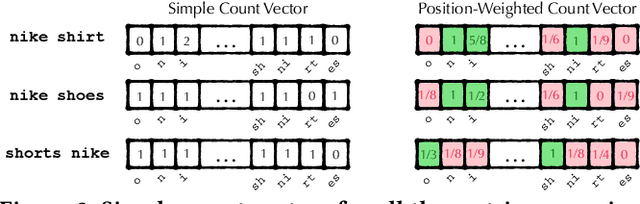
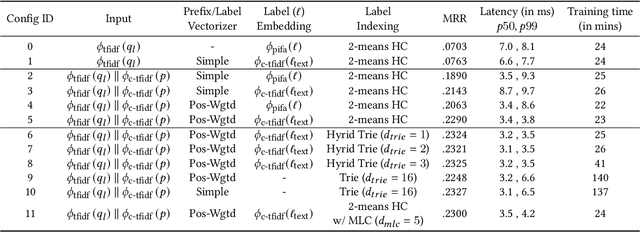
Query auto-completion is a fundamental feature in search engines where the task is to suggest plausible completions of a prefix typed in the search bar. Previous queries in the user session can provide useful context for the user's intent and can be leveraged to suggest auto-completions that are more relevant while adhering to the user's prefix. Such session-aware query auto-completions can be generated by sequence-to-sequence models; however, these generative approaches often do not meet the stringent latency requirements of responding to each user keystroke. Moreover, there is a danger of showing non-sensical queries in a generative approach. Another solution is to pre-compute a relatively small subset of relevant queries for common prefixes and rank them based on the context. However, such an approach would fail if no relevant queries for the current context are present in the pre-computed set. In this paper, we provide a solution to this problem: we take the novel approach of modeling session-aware query auto-completion as an eXtreme Multi-Label Ranking (XMR) problem where the input is the previous query in the session and the user's current prefix, while the output space is the set of millions of queries entered by users in the recent past. We adapt a popular XMR algorithm for this purpose by proposing several modifications to the key steps in the algorithm. The proposed modifications yield a 230% improvement in terms of Mean Reciprocal Rank over the baseline XMR approach on a public search logs dataset. Our approach meets the stringent latency requirements for auto-complete systems while leveraging session information in making suggestions. We show that session context leads to significant improvements in the quality of query auto-completions; in particular, for short prefixes with up to 3 characters, we see a 32% improvement over baselines that meet latency requirements.