Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Extracted Model Adversaries for Improved Black Box Attacks
Nov 02, 2020

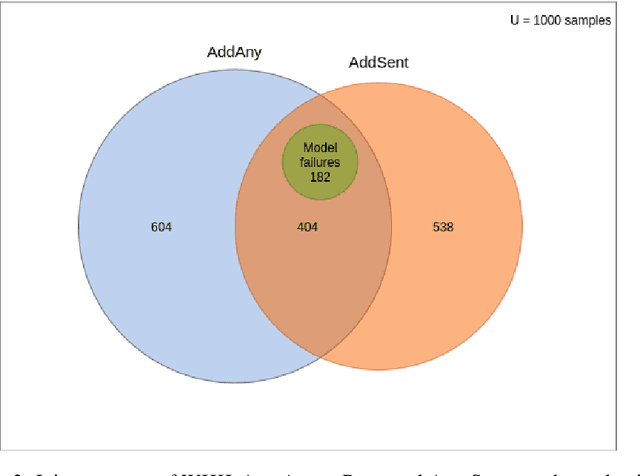
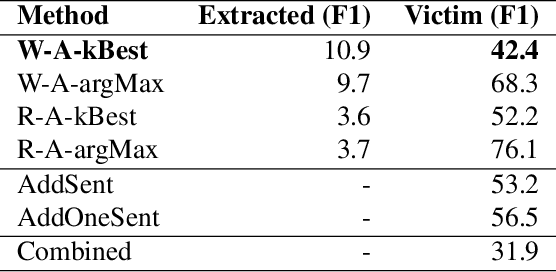
We present a method for adversarial input generation against black box models for reading comprehension based question answering. Our approach is composed of two steps. First, we approximate a victim black box model via model extraction (Krishna et al., 2020). Second, we use our own white box method to generate input perturbations that cause the approximate model to fail. These perturbed inputs are used against the victim. In experiments we find that our method improves on the efficacy of the AddAny---a white box attack---performed on the approximate model by 25% F1, and the AddSent attack---a black box attack---by 11% F1 (Jia and Liang, 2017).
* Analyzing and interpreting neural networks for NLP, 2020
Via