 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuffixDecoding: A Model-Free Approach to Speeding Up Large Language Model Inference
Paper and Code
Nov 07, 2024
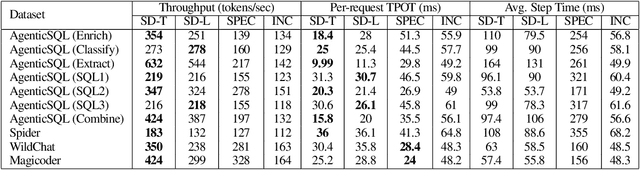


We present SuffixDecoding, a novel model-free approach to accelerating large language model (LLM) inference through speculative decoding. Unlike existing methods that rely on draft models or specialized decoding heads, SuffixDecoding leverages suffix trees built from previously generated outputs to efficiently predict candidate token sequences. Our approach enables flexible tree-structured speculation without the overhead of maintaining and orchestrating additional models. SuffixDecoding builds and dynamically updates suffix trees to capture patterns in the generated text, using them to construct speculation trees through a principled scoring mechanism based on empirical token frequencies. SuffixDecoding requires only CPU memory which is plentiful and underutilized on typical LLM serving nodes. We demonstrate that SuffixDecoding achieves competitive speedups compared to model-based approaches across diverse workloads including open-domain chat, code generation, and text-to-SQL tasks. For open-ended chat and code generation tasks, SuffixDecoding achieves up to $1.4\times$ higher output throughput than SpecInfer and up to $1.1\times$ lower time-per-token (TPOT) latency. For a proprietary multi-LLM text-to-SQL application, SuffixDecoding achieves up to $2.9\times$ higher output throughput and $3\times$ lower latency than speculative decoding. Our evaluation shows that SuffixDecoding maintains high acceptance rates even with small reference corpora of 256 examples, while continuing to improve performance as more historical outputs are incorporated.