 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-Task Large Model Training via Data Heterogeneity-aware Model Management
Paper and Code
Sep 05, 2024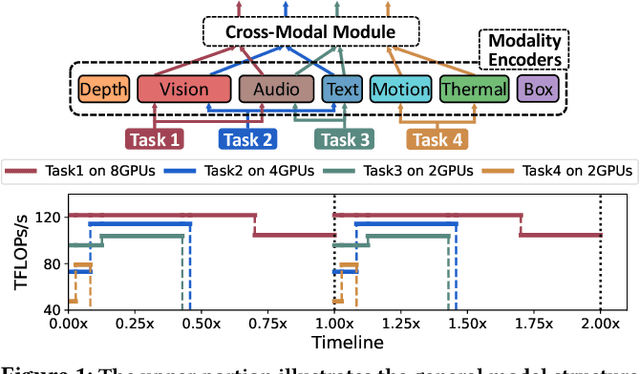

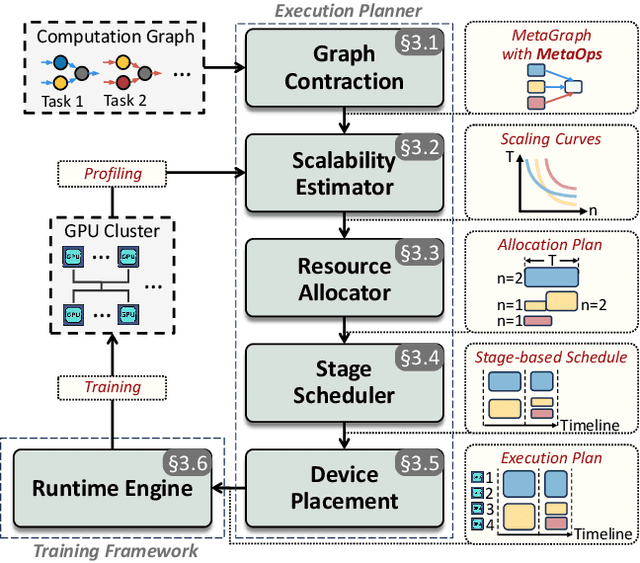
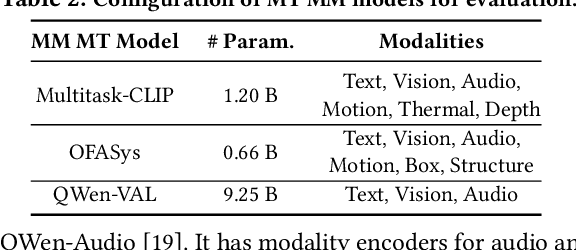
Recent foundation models are capable of handling multiple machine learning (ML) tasks and multiple data modalities with the unified base model structure and several specialized model components. However, the development of such multi-task (MT) multi-modal (MM) models poses significant model management challenges to existing training systems. Due to the sophisticated model architecture and the heterogeneous workloads of different ML tasks and data modalities, training these models usually requires massive GPU resources and suffers from sub-optimal system efficiency. In this paper, we investigate how to achieve high-performance training of large-scale MT MM models through data heterogeneity-aware model management optimization. The key idea is to decompose the model execution into stages and address the joint optimization problem sequentially, including both heterogeneity-aware workload parallelization and dependency-driven execution scheduling. Based on this, we build a prototype system and evaluate it on various large MT MM models. Experiments demonstrate the superior performance and efficiency of our system, with speedup ratio up to 71% compared to state-of-the-art training systems.