 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Graph Neural Network Training: A Survey
Paper and Code
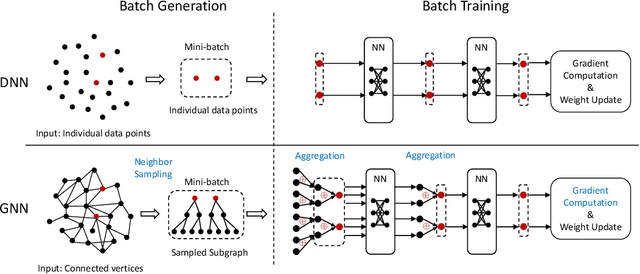

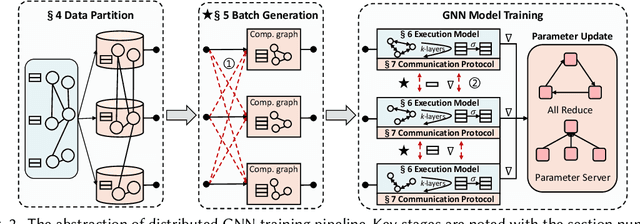
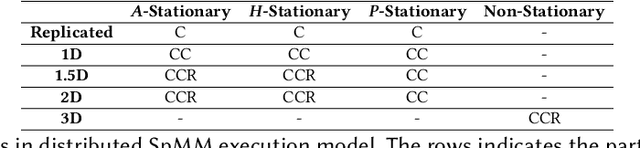
Graph neural networks (GNNs) are a type of deep learning models that learning over graphs, and have been successfully applied in many domains. Despite the effectiveness of GNNs, it is still challenging for GNNs to efficiently scale to large graphs. As a remedy, distributed computing becomes a promising solution of training large-scale GNNs, since it is able to provide abundant computing resources. However, the dependency of graph structure increases the difficulty of achieving high-efficiency distributed GNN training, which suffers from the massive communication and workload imbalance. In recent years, many efforts have been made on distributed GNN training, and an array of training algorithms and systems have been proposed. Yet, there is a lack of systematic review on the optimization techniques from graph processing to distributed execution. In this survey, we analyze three major challenges in distributed GNN training that are massive feature communication, the loss of model accuracy and workload imbalance. Then we introduce a new taxonomy for the optimization techniques in distributed GNN training that address the above challenges. The new taxonomy classifies existing techniques into four categories that are GNN data partition, GNN batch generation, GNN execution model, and GNN communication protocol.We carefully discuss the techniques in each category. In the end, we summarize existing distributed GNN systems for multi-GPUs, GPU-clusters and CPU-clusters, respectively, and give a discussion about the future direction on scalable GNNs.