 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Low-Resource Machine Translation between Chinese and Vietnamese with Back-Translation
Paper and Code
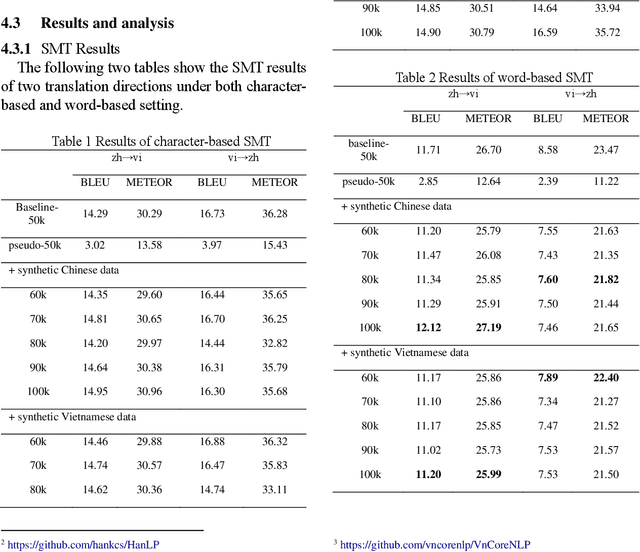
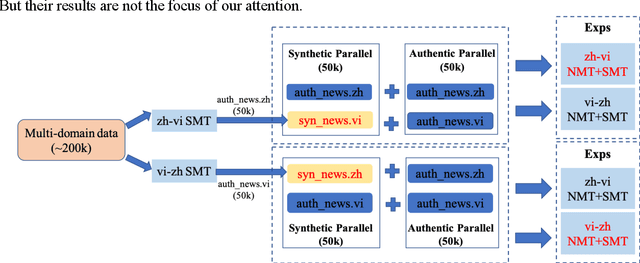

Back translation (BT) has been widely used and become one of standard techniques for data augmentation in Neural Machine Translation (NMT), BT has proven to be helpful for improving the performance of translation effectively, especially for low-resource scenarios. While most works related to BT mainly focus on European languages, few of them study languages in other areas around the world. In this paper, we investigate the impacts of BT on Asia language translations between the extremely low-resource Chinese and Vietnamese language pair. We evaluate and compare the effects of different sizes of synthetic data on both NMT and Statistical Machine Translation (SMT) models for Chinese to Vietnamese and Vietnamese to Chinese, with character-based and word-based settings. Some conclusions from previous works are partially confirmed and we also draw some other interesting findings and conclusions, which are beneficial to understand BT further.