 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Geometric Collaborative Guidance for Affordance Learning
Paper and Code
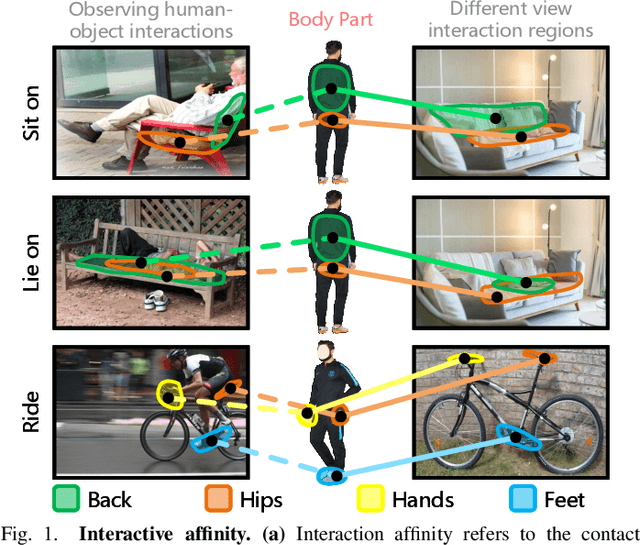


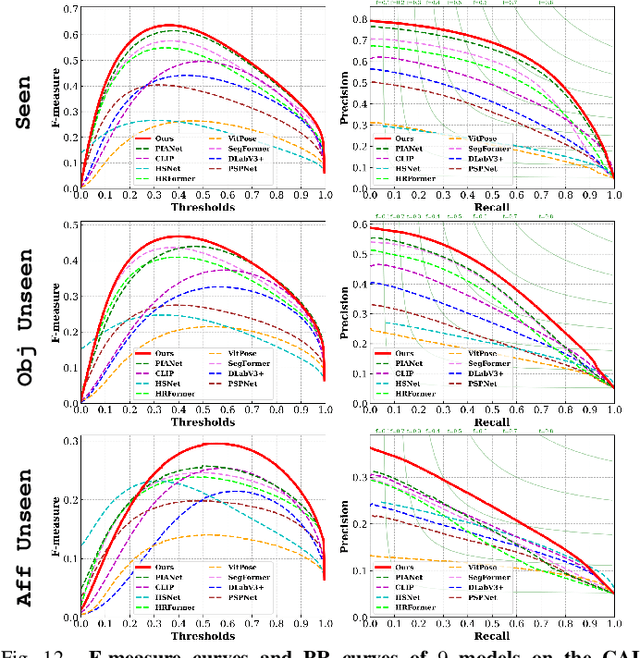
Perceiving potential ``action possibilities'' (\ie, affordance) regions of images and learning interactive functionalities of objects from human demonstration is a challenging task due to the diversity of human-object interactions. Prevailing affordance learning algorithms often adopt the label assignment paradigm and presume that there is a unique relationship between functional region and affordance label, yielding poor performance when adapting to unseen environments with large appearance variations. In this paper, we propose to leverage interactive affinity for affordance learning, \ie extracting interactive affinity from human-object interaction and transferring it to non-interactive objects. Interactive affinity, which represents the contacts between different parts of the human body and local regions of the target object, can provide inherent cues of interconnectivity between humans and objects, thereby reducing the ambiguity of the perceived action possibilities. To this end, we propose a visual-geometric collaborative guided affordance learning network that incorporates visual and geometric cues to excavate interactive affinity from human-object interactions jointly. Besides, a contact-driven affordance learning (CAL) dataset is constructed by collecting and labeling over 55,047 images. Experimental results demonstrate that our method outperforms the representative models regarding objective metrics and visual quality. Project: \href{https://github.com/lhc1224/VCR-Net}{github.com/lhc1224/VCR-Net}.