 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Doubly-Adaptive MCMC to Estimate the Gibbs Partition Function with Weak Mixing Time Bounds
Nov 14, 2021
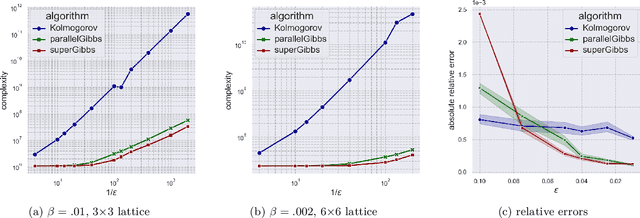
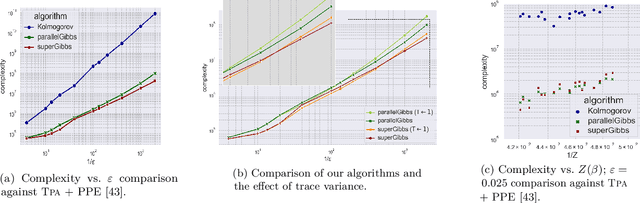
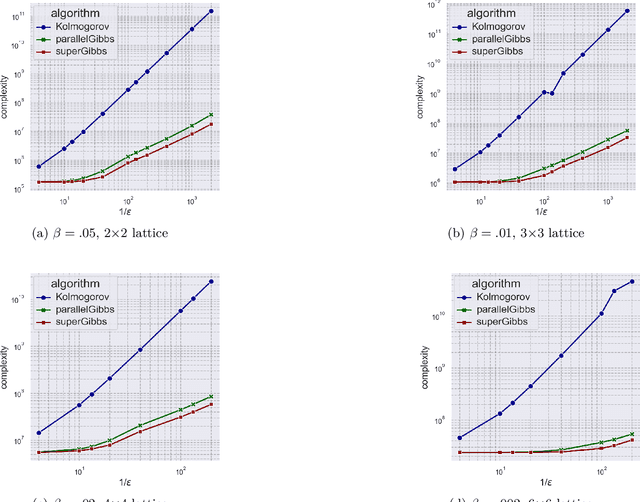
We present a novel method for reducing the computational complexity of rigorously estimating the partition functions (normalizing constants) of Gibbs (Boltzmann) distributions, which arise ubiquitously in probabilistic graphical models. A major obstacle to practical applications of Gibbs distributions is the need to estimate their partition functions. The state of the art in addressing this problem is multi-stage algorithms, which consist of a cooling schedule, and a mean estimator in each step of the schedule. While the cooling schedule in these algorithms is adaptive, the mean estimation computations use MCMC as a black-box to draw approximate samples. We develop a doubly adaptive approach, combining the adaptive cooling schedule with an adaptive MCMC mean estimator, whose number of Markov chain steps adapts dynamically to the underlying chain. Through rigorous theoretical analysis, we prove that our method outperforms the state of the art algorithms in several factors: (1) The computational complexity of our method is smaller; (2) Our method is less sensitive to loose bounds on mixing times, an inherent component in these algorithms; and (3) The improvement obtained by our method is particularly significant in the most challenging regime of high-precision estimation. We demonstrate the advantage of our method in experiments run on classic factor graphs, such as voting models and Ising models.
Context-Aware Drive-thru Recommendation Service at Fast Food Restaurants
Oct 13, 2020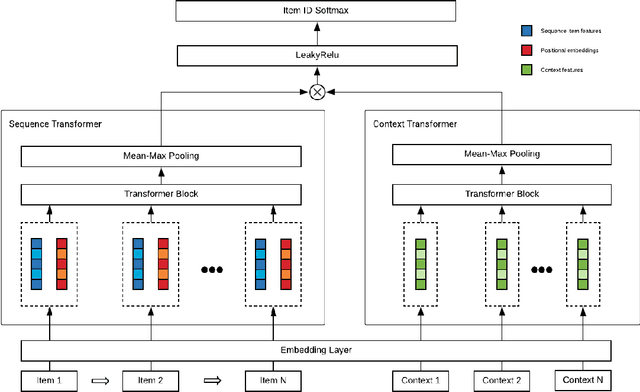

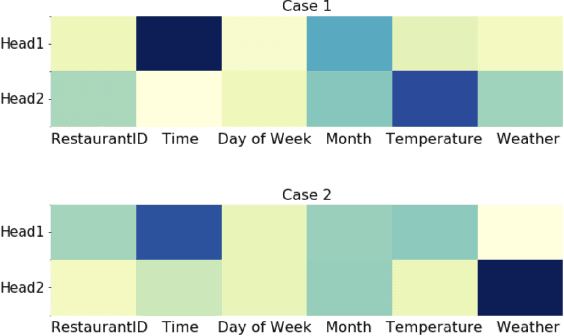
Drive-thru is a popular sales channel in the fast food industry where consumers can make food purchases without leaving their cars. Drive-thru recommendation systems allow restaurants to display food recommendations on the digital menu board as guests are making their orders. Popular recommendation models in eCommerce scenarios rely on user attributes (such as user profiles or purchase history) to generate recommendations, while such information is hard to obtain in the drive-thru use case. Thus, in this paper, we propose a new recommendation model Transformer Cross Transformer (TxT), which exploits the guest order behavior and contextual features (such as location, time, and weather) using Transformer encoders for drive-thru recommendations. Empirical results show that our TxT model achieves superior results in Burger King's drive-thru production environment compared with existing recommendation solutions. In addition, we implement a unified system to run end-to-end big data analytics and deep learning workloads on the same cluster. We find that in practice, maintaining a single big data cluster for the entire pipeline is more efficient and cost-saving. Our recommendation system is not only beneficial for drive-thru scenarios, and it can also be generalized to other customer interaction channels.