 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimally Improving Cooperative Learning in a Social Setting
May 31, 2024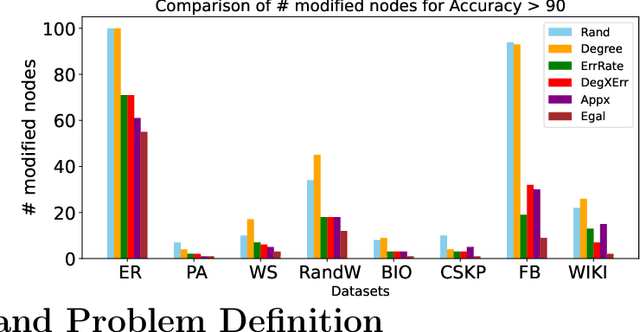
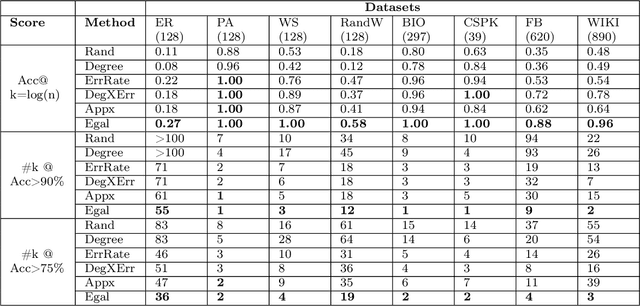
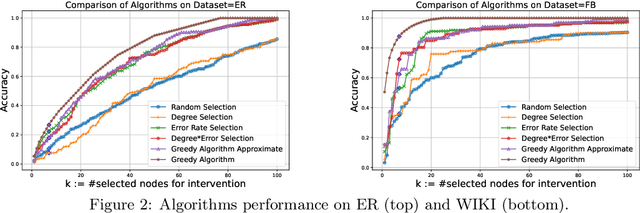
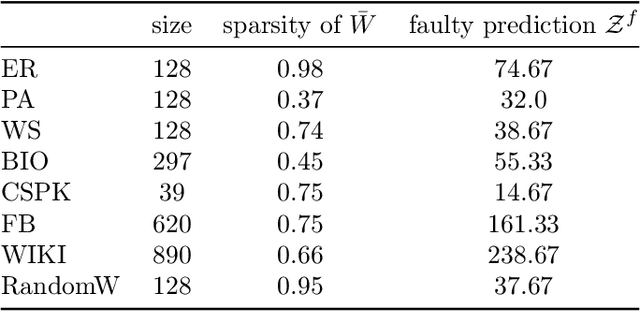
We consider a cooperative learning scenario where a collection of networked agents with individually owned classifiers dynamically update their predictions, for the same classification task, through communication or observations of each other's predictions. Clearly if highly influential vertices use erroneous classifiers, there will be a negative effect on the accuracy of all the agents in the network. We ask the following question: how can we optimally fix the prediction of a few classifiers so as maximize the overall accuracy in the entire network. To this end we consider an aggregate and an egalitarian objective function. We show a polynomial time algorithm for optimizing the aggregate objective function, and show that optimizing the egalitarian objective function is NP-hard. Furthermore, we develop approximation algorithms for the egalitarian improvement. The performance of all of our algorithms are guaranteed by mathematical analysis and backed by experiments on synthetic and real data.
Fast Doubly-Adaptive MCMC to Estimate the Gibbs Partition Function with Weak Mixing Time Bounds
Nov 14, 2021
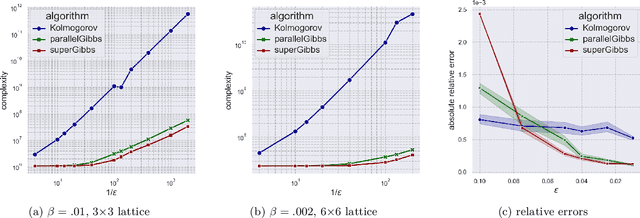
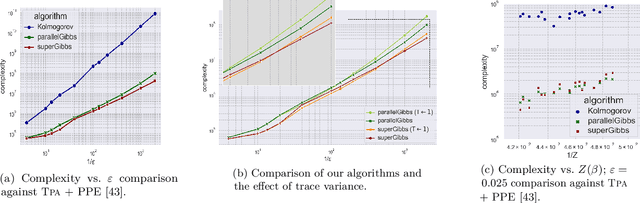
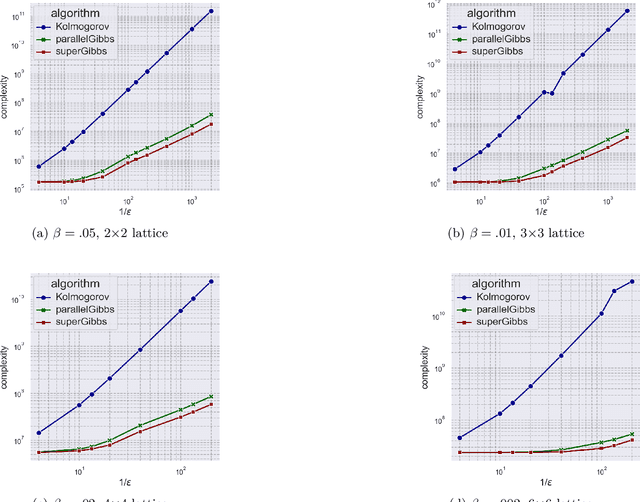
We present a novel method for reducing the computational complexity of rigorously estimating the partition functions (normalizing constants) of Gibbs (Boltzmann) distributions, which arise ubiquitously in probabilistic graphical models. A major obstacle to practical applications of Gibbs distributions is the need to estimate their partition functions. The state of the art in addressing this problem is multi-stage algorithms, which consist of a cooling schedule, and a mean estimator in each step of the schedule. While the cooling schedule in these algorithms is adaptive, the mean estimation computations use MCMC as a black-box to draw approximate samples. We develop a doubly adaptive approach, combining the adaptive cooling schedule with an adaptive MCMC mean estimator, whose number of Markov chain steps adapts dynamically to the underlying chain. Through rigorous theoretical analysis, we prove that our method outperforms the state of the art algorithms in several factors: (1) The computational complexity of our method is smaller; (2) Our method is less sensitive to loose bounds on mixing times, an inherent component in these algorithms; and (3) The improvement obtained by our method is particularly significant in the most challenging regime of high-precision estimation. We demonstrate the advantage of our method in experiments run on classic factor graphs, such as voting models and Ising models.