 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorner-to-Center Long-range Context Model for Efficient Learned Image Compression
Paper and Code
Nov 29, 2023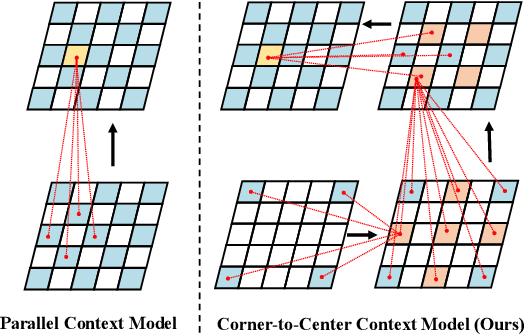
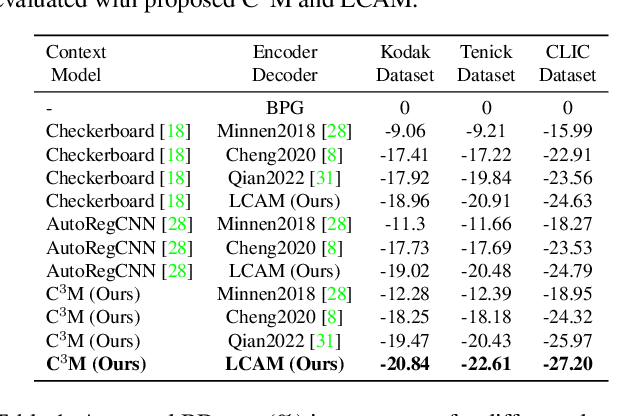
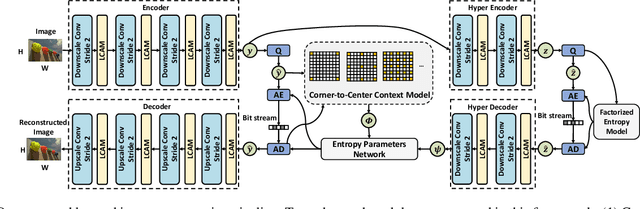

In the framework of learned image compression, the context model plays a pivotal role in capturing the dependencies among latent representations. To reduce the decoding time resulting from the serial autoregressive context model, the parallel context model has been proposed as an alternative that necessitates only two passes during the decoding phase, thus facilitating efficient image compression in real-world scenarios. However, performance degradation occurs due to its incomplete casual context. To tackle this issue, we conduct an in-depth analysis of the performance degradation observed in existing parallel context models, focusing on two aspects: the Quantity and Quality of information utilized for context prediction and decoding. Based on such analysis, we propose the \textbf{Corner-to-Center transformer-based Context Model (C$^3$M)} designed to enhance context and latent predictions and improve rate-distortion performance. Specifically, we leverage the logarithmic-based prediction order to predict more context features from corner to center progressively. In addition, to enlarge the receptive field in the analysis and synthesis transformation, we use the Long-range Crossing Attention Module (LCAM) in the encoder/decoder to capture the long-range semantic information by assigning the different window shapes in different channels. Extensive experimental evaluations show that the proposed method is effective and outperforms the state-of-the-art parallel methods. Finally, according to the subjective analysis, we suggest that improving the detailed representation in transformer-based image compression is a promising direction to be explored.