 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBVI-UGC: A Video Quality Database for User-Generated Content Transcoding
Aug 13, 2024



In recent years, user-generated content (UGC) has become one of the major video types consumed via streaming networks. Numerous research contributions have focused on assessing its visual quality through subjective tests and objective modeling. In most cases, objective assessments are based on a no-reference scenario, where the corresponding reference content is assumed not to be available. However, full-reference video quality assessment is also important for UGC in the delivery pipeline, particularly associated with the video transcoding process. In this context, we present a new UGC video quality database, BVI-UGC, for user-generated content transcoding, which contains 60 (non-pristine) reference videos and 1,080 test sequences. In this work, we simulated the creation of non-pristine reference sequences (with a wide range of compression distortions), typical of content uploaded to UGC platforms for transcoding. A comprehensive crowdsourced subjective study was then conducted involving more than 3,500 human participants. Based on this collected subjective data, we benchmarked the performance of 10 full-reference and 11 no-reference quality metrics. Our results demonstrate the poor performance (SROCC values are lower than 0.6) of these metrics in predicting the perceptual quality of UGC in two different scenarios (with or without a reference).
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024



This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.
Full-reference Video Quality Assessment for User Generated Content Transcoding
Dec 19, 2023



Unlike video coding for professional content, the delivery pipeline of User Generated Content (UGC) involves transcoding where unpristine reference content needs to be compressed repeatedly. In this work, we observe that existing full-/no-reference quality metrics fail to accurately predict the perceptual quality difference between transcoded UGC content and the corresponding unpristine references. Therefore, they are unsuited for guiding the rate-distortion optimisation process in the transcoding process. In this context, we propose a bespoke full-reference deep video quality metric for UGC transcoding. The proposed method features a transcoding-specific weakly supervised training strategy employing a quality ranking-based Siamese structure. The proposed method is evaluated on the YouTube-UGC VP9 subset and the LIVE-Wild database, demonstrating state-of-the-art performance compared to existing VQA methods.
Enhancing HDR Video Compression through CNN-based Effective Bit Depth Adaptation
Jul 18, 2022


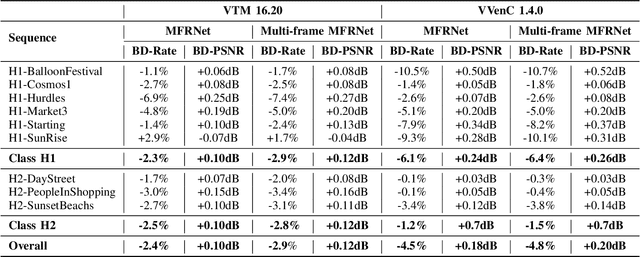
It is well known that high dynamic range (HDR) video can provide more immersive visual experiences compared to conventional standard dynamic range content. However, HDR content is typically more challenging to encode due to the increased detail associated with the wider dynamic range. In this paper, we improve HDR compression performance using the effective bit depth adaptation approach (EBDA). This method reduces the effective bit depth of the original video content before encoding and reconstructs the full bit depth using a CNN-based up-sampling method at the decoder. In this work, we modify the MFRNet network architecture to enable multiple frame processing, and the new network, multi-frame MFRNet, has been integrated into the EBDA framework using two Versatile Video Coding (VVC) host codecs: VTM 16.2 and the Fraunhofer Versatile Video Encoder (VVenC 1.4.0). The proposed approach was evaluated under the JVET HDR Common Test Conditions using the Random Access configuration. The results show coding gains over both the original VVC VTM 16.2 and VVenC 1.4.0 (w/o EBDA) on JVET HDR tested sequences, with average bitrate savings of 2.9% (over VTM) and 4.8% (against VVenC) based on the Bjontegaard Delta measurement. The source code of multi-frame MFRNet has been released at https://github.com/fan-aaron-zhang/MF-MFRNet.
Towards High-Quality Temporal Action Detection with Sparse Proposals
Sep 18, 2021
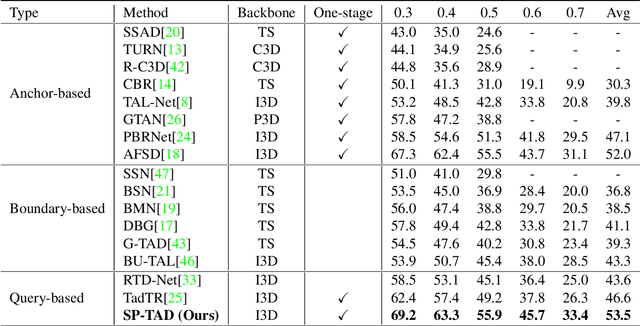

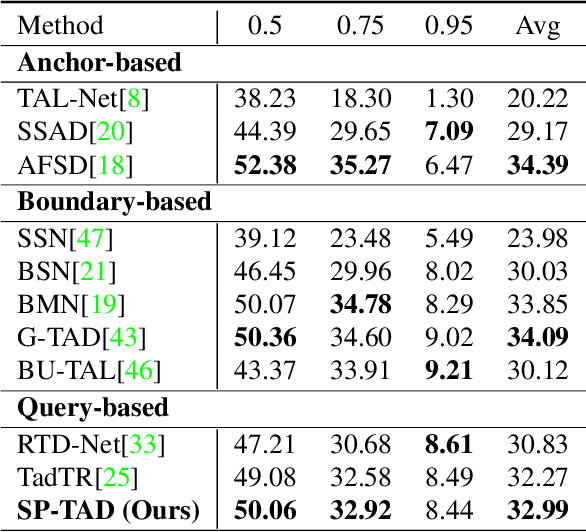
Temporal Action Detection (TAD) is an essential and challenging topic in video understanding, aiming to localize the temporal segments containing human action instances and predict the action categories. The previous works greatly rely upon dense candidates either by designing varying anchors or enumerating all the combinations of boundaries on video sequences; therefore, they are related to complicated pipelines and sensitive hand-crafted designs. Recently, with the resurgence of Transformer, query-based methods have tended to become the rising solutions for their simplicity and flexibility. However, there still exists a performance gap between query-based methods and well-established methods. In this paper, we identify the main challenge lies in the large variants of action duration and the ambiguous boundaries for short action instances; nevertheless, quadratic-computational global attention prevents query-based methods to build multi-scale feature maps. Towards high-quality temporal action detection, we introduce Sparse Proposals to interact with the hierarchical features. In our method, named SP-TAD, each proposal attends to a local segment feature in the temporal feature pyramid. The local interaction enables utilization of high-resolution features to preserve action instances details. Extensive experiments demonstrate the effectiveness of our method, especially under high tIoU thresholds. E.g., we achieve the state-of-the-art performance on THUMOS14 (45.7% on mAP@0.6, 33.4% on mAP@0.7 and 53.5% on mAP@Avg) and competitive results on ActivityNet-1.3 (32.99% on mAP@Avg). Code will be made available at https://github.com/wjn922/SP-TAD.
TEST: an End-to-End Network Traffic Examination and Identification Framework Based on Spatio-Temporal Features Extraction
Aug 26, 2019

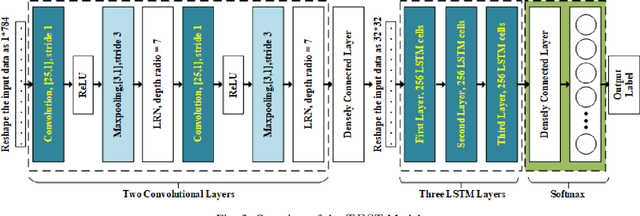
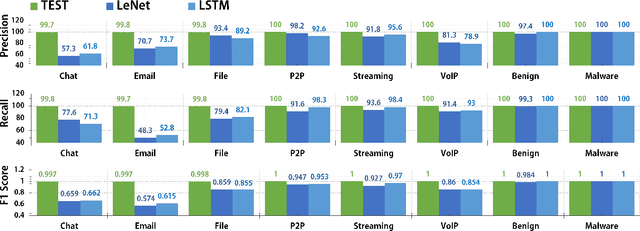
With more encrypted network traffic gets involved in the Internet, how to effectively identify network traffic has become a top priority in the field. Accurate identification of the network traffic is the footstone of basic network services, say QoE, bandwidth allocation, and IDS. Previous identification methods either cannot deal with encrypted traffics or require experts to select tons of features to attain a relatively decent accuracy.In this paper, we present a Deep Learning based end-to-end network traffic identification framework, termed TEST, to avoid the aforementioned problems. CNN and LSTM are combined and implemented to help the machine automatically extract features from both special and time-related features of the raw traffic. The presented framework has two layers of structure, which made it possible to attain a remarkable accuracy on both encrypted traffic classification and intrusion detection tasks. The experimental results demonstrate that our model can outperform previous methods with a state-of-the-art accuracy of 99.98%.