 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankDVQA-mini: Knowledge Distillation-Driven Deep Video Quality Assessment
Paper and Code
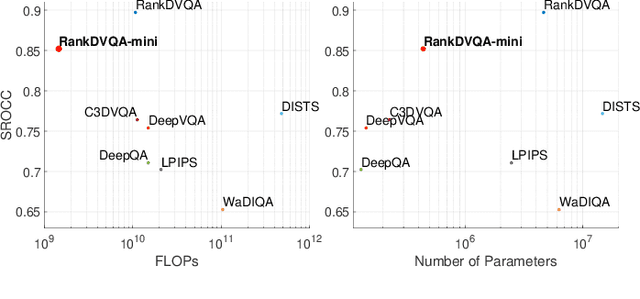
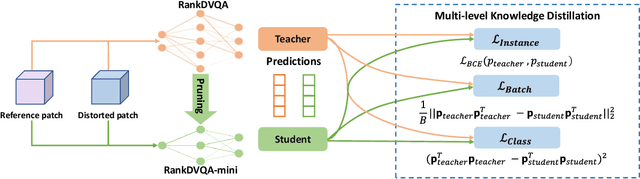
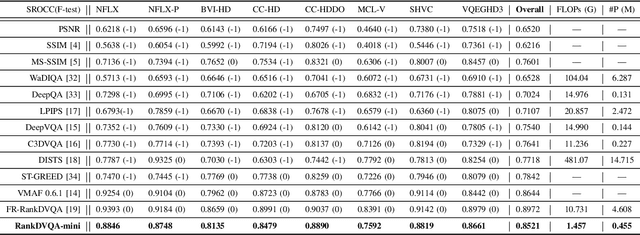
Deep learning-based video quality assessment (deep VQA) has demonstrated significant potential in surpassing conventional metrics, with promising improvements in terms of correlation with human perception. However, the practical deployment of such deep VQA models is often limited due to their high computational complexity and large memory requirements. To address this issue, we aim to significantly reduce the model size and runtime of one of the state-of-the-art deep VQA methods, RankDVQA, by employing a two-phase workflow that integrates pruning-driven model compression with multi-level knowledge distillation. The resulting lightweight quality metric, RankDVQA-mini, requires less than 10% of the model parameters compared to its full version (14% in terms of FLOPs), while still retaining a quality prediction performance that is superior to most existing deep VQA methods. The source code of the RankDVQA-mini has been released at https://chenfeng-bristol.github.io/RankDVQA-mini/ for public evaluation.