 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDMVFI: Video Frame Interpolation with Latent Diffusion Models
Paper and Code

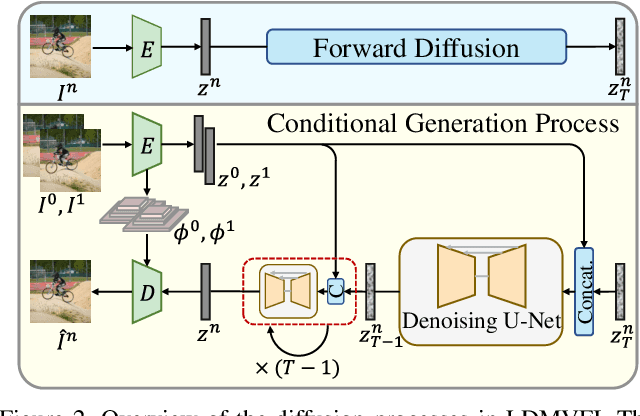


Existing works on video frame interpolation (VFI) mostly employ deep neural networks trained to minimize the L1 or L2 distance between their outputs and ground-truth frames. Despite recent advances, existing VFI methods tend to produce perceptually inferior results, particularly for challenging scenarios including large motions and dynamic textures. Towards developing perceptually-oriented VFI methods, we propose latent diffusion model-based VFI, LDMVFI. This approaches the VFI problem from a generative perspective by formulating it as a conditional generation problem. As the first effort to address VFI using latent diffusion models, we rigorously benchmark our method following the common evaluation protocol adopted in the existing VFI literature. Our quantitative experiments and user study indicate that LDMVFI is able to interpolate video content with superior perceptual quality compared to the state of the art, even in the high-resolution regime. Our source code will be made available here.