 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoomEditor++: A Parameter-Sharing Diffusion Architecture for High-Fidelity Furniture Synthesis
Dec 19, 2025Virtual furniture synthesis, which seamlessly integrates reference objects into indoor scenes while maintaining geometric coherence and visual realism, holds substantial promise for home design and e-commerce applications. However, this field remains underexplored due to the scarcity of reproducible benchmarks and the limitations of existing image composition methods in achieving high-fidelity furniture synthesis while preserving background integrity. To overcome these challenges, we first present RoomBench++, a comprehensive and publicly available benchmark dataset tailored for this task. It consists of 112,851 training pairs and 1,832 testing pairs drawn from both real-world indoor videos and realistic home design renderings, thereby supporting robust training and evaluation under practical conditions. Then, we propose RoomEditor++, a versatile diffusion-based architecture featuring a parameter-sharing dual diffusion backbone, which is compatible with both U-Net and DiT architectures. This design unifies the feature extraction and inpainting processes for reference and background images. Our in-depth analysis reveals that the parameter-sharing mechanism enforces aligned feature representations, facilitating precise geometric transformations, texture preservation, and seamless integration. Extensive experiments validate that RoomEditor++ is superior over state-of-the-art approaches in terms of quantitative metrics, qualitative assessments, and human preference studies, while highlighting its strong generalization to unseen indoor scenes and general scenes without task-specific fine-tuning. The dataset and source code are available at \url{https://github.com/stonecutter-21/roomeditor}.
AMU-Tuning: Effective Logit Bias for CLIP-based Few-shot Learning
Apr 13, 2024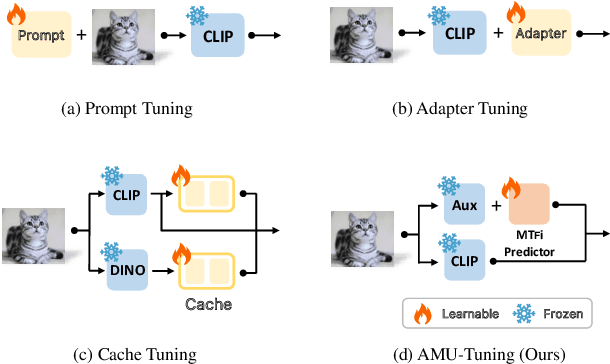

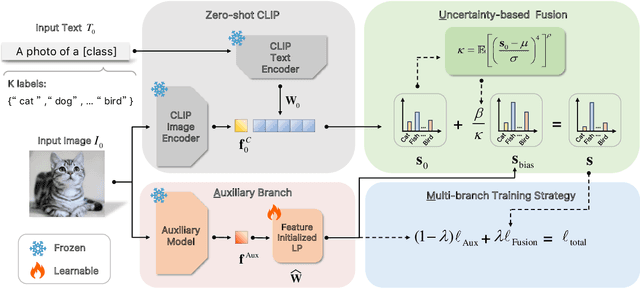
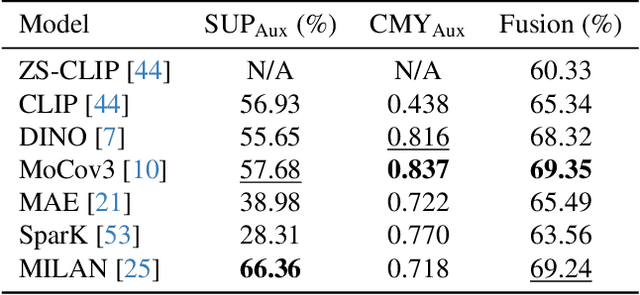
Recently, pre-trained vision-language models (e.g., CLIP) have shown great potential in few-shot learning and attracted a lot of research interest. Although efforts have been made to improve few-shot ability of CLIP, key factors on the effectiveness of existing methods have not been well studied, limiting further exploration of CLIP's potential in few-shot learning. In this paper, we first introduce a unified formulation to analyze CLIP-based few-shot learning methods from a perspective of logit bias, which encourages us to learn an effective logit bias for further improving performance of CLIP-based few-shot learning methods. To this end, we disassemble three key components involved in computation of logit bias (i.e., logit features, logit predictor, and logit fusion) and empirically analyze the effect on performance of few-shot classification. Based on analysis of key components, this paper proposes a novel AMU-Tuning method to learn effective logit bias for CLIP-based few-shot classification. Specifically, our AMU-Tuning predicts logit bias by exploiting the appropriate $\underline{\textbf{A}}$uxiliary features, which are fed into an efficient feature-initialized linear classifier with $\underline{\textbf{M}}$ulti-branch training. Finally, an $\underline{\textbf{U}}$ncertainty-based fusion is developed to incorporate logit bias into CLIP for few-shot classification. The experiments are conducted on several widely used benchmarks, and the results show AMU-Tuning clearly outperforms its counterparts while achieving state-of-the-art performance of CLIP-based few-shot learning without bells and whistles.
Tuning Pre-trained Model via Moment Probing
Jul 21, 2023Recently, efficient fine-tuning of large-scale pre-trained models has attracted increasing research interests, where linear probing (LP) as a fundamental module is involved in exploiting the final representations for task-dependent classification. However, most of the existing methods focus on how to effectively introduce a few of learnable parameters, and little work pays attention to the commonly used LP module. In this paper, we propose a novel Moment Probing (MP) method to further explore the potential of LP. Distinguished from LP which builds a linear classification head based on the mean of final features (e.g., word tokens for ViT) or classification tokens, our MP performs a linear classifier on feature distribution, which provides the stronger representation ability by exploiting richer statistical information inherent in features. Specifically, we represent feature distribution by its characteristic function, which is efficiently approximated by using first- and second-order moments of features. Furthermore, we propose a multi-head convolutional cross-covariance (MHC$^3$) to compute second-order moments in an efficient and effective manner. By considering that MP could affect feature learning, we introduce a partially shared module to learn two recalibrating parameters (PSRP) for backbones based on MP, namely MP$_{+}$. Extensive experiments on ten benchmarks using various models show that our MP significantly outperforms LP and is competitive with counterparts at less training cost, while our MP$_{+}$ achieves state-of-the-art performance.