 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIDAO: Towards Limited Interventions for Debiasing (Large) Language Models
Paper and Code
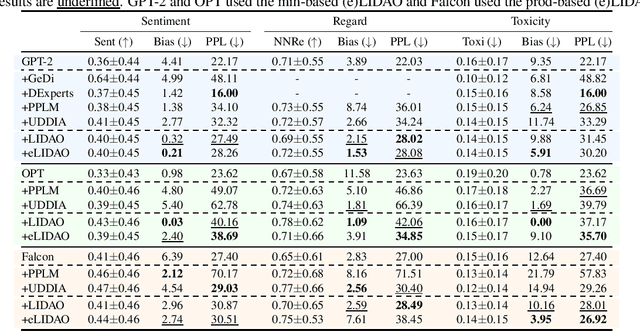
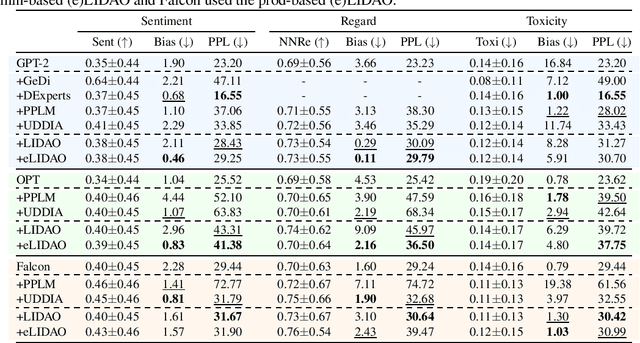

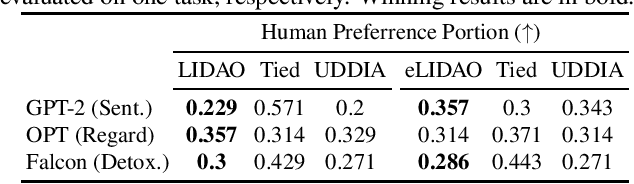
Large language models (LLMs) have achieved impressive performance on various natural language generation tasks. Nonetheless, they suffer from generating negative and harmful contents that are biased against certain demographic groups (e.g., female), raising severe fairness concerns. As remedies, prior works intervened the generation by removing attitude or demographic information, inevitably degrading the generation quality and resulting in notable \textit{fairness-fluency} trade-offs. However, it is still under-explored to what extent the fluency \textit{has to} be affected in order to achieve a desired level of fairness. In this work, we conduct the first formal study from an information-theoretic perspective. We show that previous approaches are excessive for debiasing and propose LIDAO, a general framework to debias a (L)LM at a better fluency provably. We further robustify LIDAO in adversarial scenarios, where a carefully-crafted prompt may stimulate LLMs exhibiting instruction-following abilities to generate texts with fairness issue appears only when the prompt is also taken into account. Experiments on three LMs ranging from 0.7B to 7B parameters demonstrate the superiority of our method.