 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmaller But Better: Unifying Layout Generation with Smaller Large Language Models
Feb 19, 2025We propose LGGPT, an LLM-based model tailored for unified layout generation. First, we propose Arbitrary Layout Instruction (ALI) and Universal Layout Response (ULR) as the uniform I/O template. ALI accommodates arbitrary layout generation task inputs across multiple layout domains, enabling LGGPT to unify both task-generic and domain-generic layout generation hitherto unexplored. Collectively, ALI and ULR boast a succinct structure that forgoes superfluous tokens typically found in existing HTML-based formats, facilitating efficient instruction tuning and boosting unified generation performance. In addition, we propose an Interval Quantization Encoding (IQE) strategy that compresses ALI into a more condensed structure. IQE precisely preserves valid layout clues while eliminating the less informative placeholders, facilitating LGGPT to capture complex and variable layout generation conditions during the unified training process. Experimental results demonstrate that LGGPT achieves superior or on par performance compared to existing methods. Notably, LGGPT strikes a prominent balance between proficiency and efficiency with a compact 1.5B parameter LLM, which beats prior 7B or 175B models even in the most extensive and challenging unified scenario. Furthermore, we underscore the necessity of employing LLMs for unified layout generation and suggest that 1.5B could be an optimal parameter size by comparing LLMs of varying scales. Code is available at https://github.com/NiceRingNode/LGGPT.
TongGu: Mastering Classical Chinese Understanding with Knowledge-Grounded Large Language Models
Jul 04, 2024Classical Chinese is a gateway to the rich heritage and wisdom of ancient China, yet its complexities pose formidable comprehension barriers for most modern people without specialized knowledge. While Large Language Models (LLMs) have shown remarkable capabilities in Natural Language Processing (NLP), they struggle with Classical Chinese Understanding (CCU), especially in data-demanding and knowledge-intensive tasks. In response to this dilemma, we propose \textbf{TongGu} (mean understanding ancient and modern), the first CCU-specific LLM, underpinned by three core contributions. First, we construct a two-stage instruction-tuning dataset ACCN-INS derived from rich classical Chinese corpora, aiming to unlock the full CCU potential of LLMs. Second, we propose Redundancy-Aware Tuning (RAT) to prevent catastrophic forgetting, enabling TongGu to acquire new capabilities while preserving its foundational knowledge. Third, we present a CCU Retrieval-Augmented Generation (CCU-RAG) technique to reduce hallucinations based on knowledge-grounding. Extensive experiments across 24 diverse CCU tasks validate TongGu's superior ability, underscoring the effectiveness of RAT and CCU-RAG. The model and dataset will be public available.
C$^{3}$Bench: A Comprehensive Classical Chinese Understanding Benchmark for Large Language Models
May 28, 2024Classical Chinese Understanding (CCU) holds significant value in preserving and exploration of the outstanding traditional Chinese culture. Recently, researchers have attempted to leverage the potential of Large Language Models (LLMs) for CCU by capitalizing on their remarkable comprehension and semantic capabilities. However, no comprehensive benchmark is available to assess the CCU capabilities of LLMs. To fill this gap, this paper introduces C$^{3}$bench, a Comprehensive Classical Chinese understanding benchmark, which comprises 50,000 text pairs for five primary CCU tasks, including classification, retrieval, named entity recognition, punctuation, and translation. Furthermore, the data in C$^{3}$bench originates from ten different domains, covering most of the categories in classical Chinese. Leveraging the proposed C$^{3}$bench, we extensively evaluate the quantitative performance of 15 representative LLMs on all five CCU tasks. Our results not only establish a public leaderboard of LLMs' CCU capabilities but also gain some findings. Specifically, existing LLMs are struggle with CCU tasks and still inferior to supervised models. Additionally, the results indicate that CCU is a task that requires special attention. We believe this study could provide a standard benchmark, comprehensive baselines, and valuable insights for the future advancement of LLM-based CCU research. The evaluation pipeline and dataset are available at \url{https://github.com/SCUT-DLVCLab/C3bench}.
Datasets for Large Language Models: A Comprehensive Survey
Feb 28, 2024


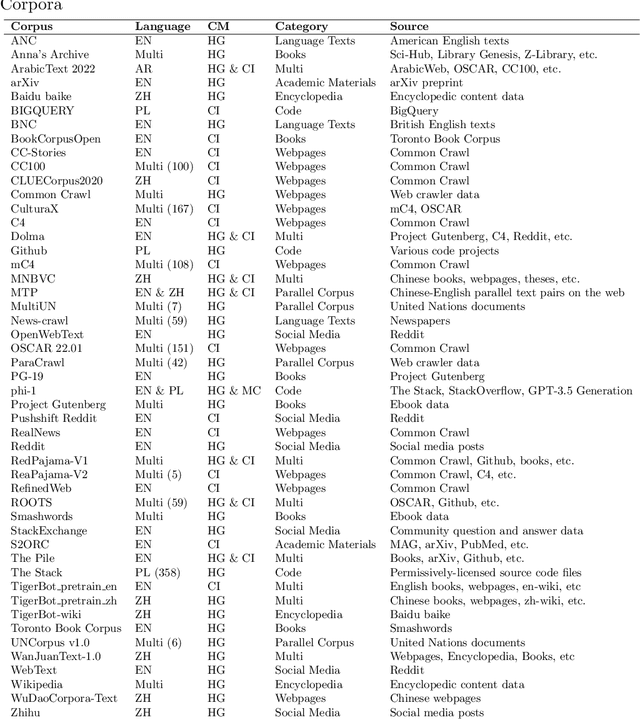
This paper embarks on an exploration into the Large Language Model (LLM) datasets, which play a crucial role in the remarkable advancements of LLMs. The datasets serve as the foundational infrastructure analogous to a root system that sustains and nurtures the development of LLMs. Consequently, examination of these datasets emerges as a critical topic in research. In order to address the current lack of a comprehensive overview and thorough analysis of LLM datasets, and to gain insights into their current status and future trends, this survey consolidates and categorizes the fundamental aspects of LLM datasets from five perspectives: (1) Pre-training Corpora; (2) Instruction Fine-tuning Datasets; (3) Preference Datasets; (4) Evaluation Datasets; (5) Traditional Natural Language Processing (NLP) Datasets. The survey sheds light on the prevailing challenges and points out potential avenues for future investigation. Additionally, a comprehensive review of the existing available dataset resources is also provided, including statistics from 444 datasets, covering 8 language categories and spanning 32 domains. Information from 20 dimensions is incorporated into the dataset statistics. The total data size surveyed surpasses 774.5 TB for pre-training corpora and 700M instances for other datasets. We aim to present the entire landscape of LLM text datasets, serving as a comprehensive reference for researchers in this field and contributing to future studies. Related resources are available at: https://github.com/lmmlzn/Awesome-LLMs-Datasets.