 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURaG: Unified Retrieval and Generation in Multimodal LLMs for Efficient Long Document Understanding
Nov 13, 2025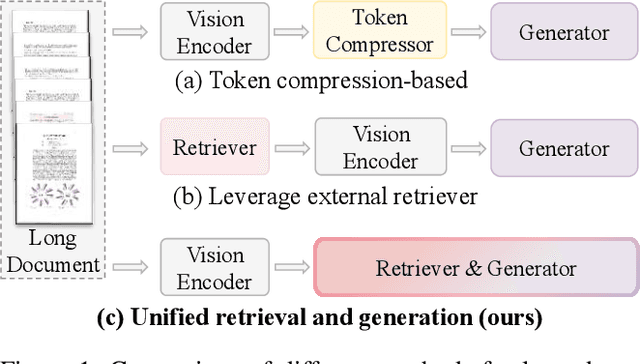
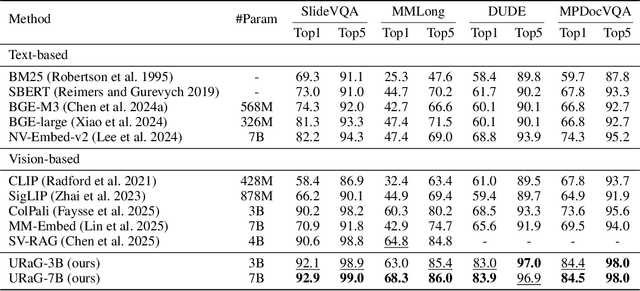
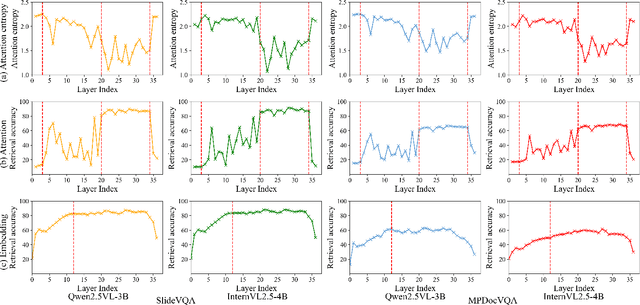
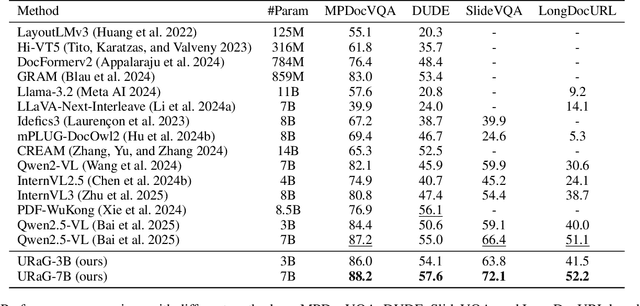
Recent multimodal large language models (MLLMs) still struggle with long document understanding due to two fundamental challenges: information interference from abundant irrelevant content, and the quadratic computational cost of Transformer-based architectures. Existing approaches primarily fall into two categories: token compression, which sacrifices fine-grained details; and introducing external retrievers, which increase system complexity and prevent end-to-end optimization. To address these issues, we conduct an in-depth analysis and observe that MLLMs exhibit a human-like coarse-to-fine reasoning pattern: early Transformer layers attend broadly across the document, while deeper layers focus on relevant evidence pages. Motivated by this insight, we posit that the inherent evidence localization capabilities of MLLMs can be explicitly leveraged to perform retrieval during the reasoning process, facilitating efficient long document understanding. To this end, we propose URaG, a simple-yet-effective framework that Unifies Retrieval and Generation within a single MLLM. URaG introduces a lightweight cross-modal retrieval module that converts the early Transformer layers into an efficient evidence selector, identifying and preserving the most relevant pages while discarding irrelevant content. This design enables the deeper layers to concentrate computational resources on pertinent information, improving both accuracy and efficiency. Extensive experiments demonstrate that URaG achieves state-of-the-art performance while reducing computational overhead by 44-56%. The code is available at https://github.com/shi-yx/URaG.
PEneo: Unifying Line Extraction, Line Grouping, and Entity Linking for End-to-end Document Pair Extraction
Jan 07, 2024



Document pair extraction aims to identify key and value entities as well as their relationships from visually-rich documents. Most existing methods divide it into two separate tasks: semantic entity recognition (SER) and relation extraction (RE). However, simply concatenating SER and RE serially can lead to severe error propagation, and it fails to handle cases like multi-line entities in real scenarios. To address these issues, this paper introduces a novel framework, PEneo (Pair Extraction new decoder option), which performs document pair extraction in a unified pipeline, incorporating three concurrent sub-tasks: line extraction, line grouping, and entity linking. This approach alleviates the error accumulation problem and can handle the case of multi-line entities. Furthermore, to better evaluate the model's performance and to facilitate future research on pair extraction, we introduce RFUND, a re-annotated version of the commonly used FUNSD and XFUND datasets, to make them more accurate and cover realistic situations. Experiments on various benchmarks demonstrate PEneo's superiority over previous pipelines, boosting the performance by a large margin (e.g., 19.89%-22.91% F1 score on RFUND-EN) when combined with various backbones like LiLT and LayoutLMv3, showing its effectiveness and generality. Codes and the new annotations will be open to the public.
Exploring OCR Capabilities of GPT-4V : A Quantitative and In-depth Evaluation
Oct 29, 2023



This paper presents a comprehensive evaluation of the Optical Character Recognition (OCR) capabilities of the recently released GPT-4V(ision), a Large Multimodal Model (LMM). We assess the model's performance across a range of OCR tasks, including scene text recognition, handwritten text recognition, handwritten mathematical expression recognition, table structure recognition, and information extraction from visually-rich document. The evaluation reveals that GPT-4V performs well in recognizing and understanding Latin contents, but struggles with multilingual scenarios and complex tasks. Specifically, it showed limitations when dealing with non-Latin languages and complex tasks such as handwriting mathematical expression recognition, table structure recognition, and end-to-end semantic entity recognition and pair extraction from document image. Based on these observations, we affirm the necessity and continued research value of specialized OCR models. In general, despite its versatility in handling diverse OCR tasks, GPT-4V does not outperform existing state-of-the-art OCR models. How to fully utilize pre-trained general-purpose LMMs such as GPT-4V for OCR downstream tasks remains an open problem. The study offers a critical reference for future research in OCR with LMMs. Evaluation pipeline and results are available at https://github.com/SCUT-DLVCLab/GPT-4V_OCR.