 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel View Synthesis with Diffusion Models
Paper and Code
Oct 06, 2022
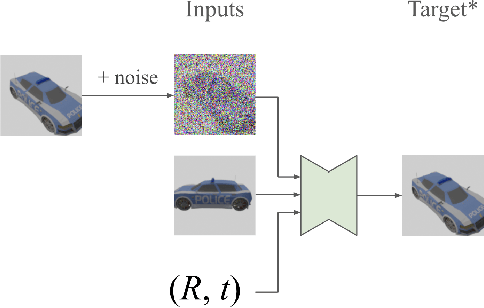
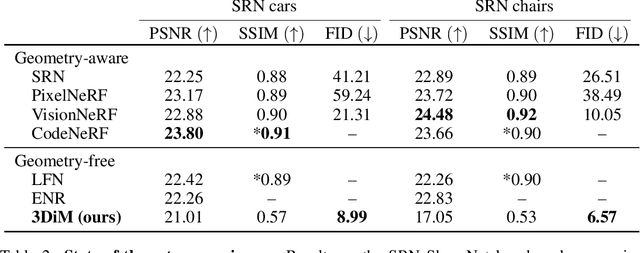
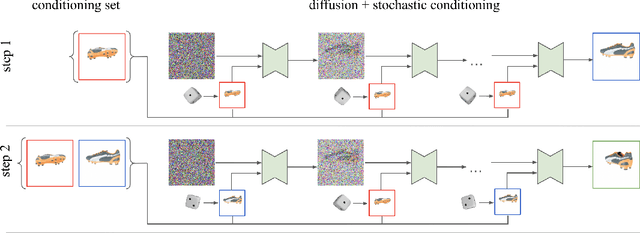
We present 3DiM, a diffusion model for 3D novel view synthesis, which is able to translate a single input view into consistent and sharp completions across many views. The core component of 3DiM is a pose-conditional image-to-image diffusion model, which takes a source view and its pose as inputs, and generates a novel view for a target pose as output. 3DiM can generate multiple views that are 3D consistent using a novel technique called stochastic conditioning. The output views are generated autoregressively, and during the generation of each novel view, one selects a random conditioning view from the set of available views at each denoising step. We demonstrate that stochastic conditioning significantly improves the 3D consistency of a naive sampler for an image-to-image diffusion model, which involves conditioning on a single fixed view. We compare 3DiM to prior work on the SRN ShapeNet dataset, demonstrating that 3DiM's generated completions from a single view achieve much higher fidelity, while being approximately 3D consistent. We also introduce a new evaluation methodology, 3D consistency scoring, to measure the 3D consistency of a generated object by training a neural field on the model's output views. 3DiM is geometry free, does not rely on hyper-networks or test-time optimization for novel view synthesis, and allows a single model to easily scale to a large number of scenes.