 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoduo: Learning Dense Visual Correspondence from Unsupervised Semantic-Aware Flow
Paper and Code
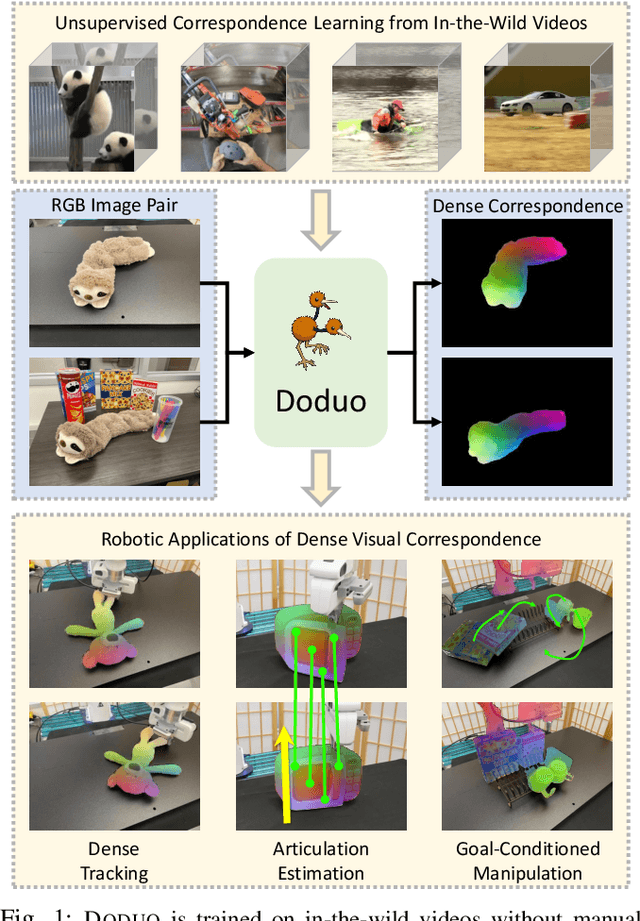
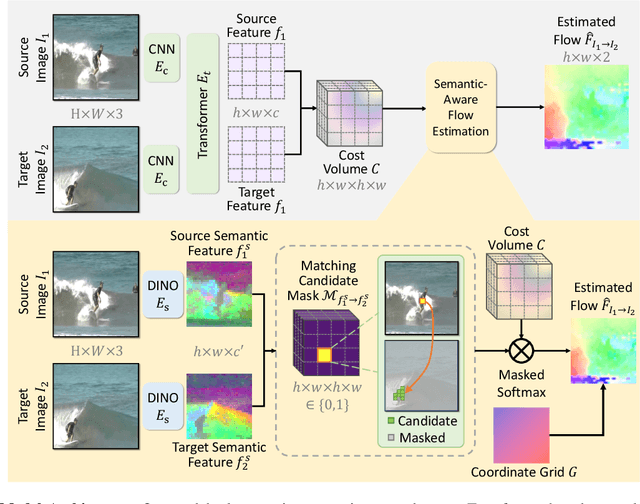
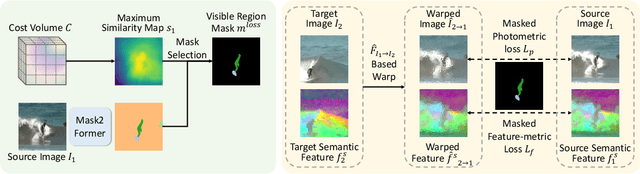
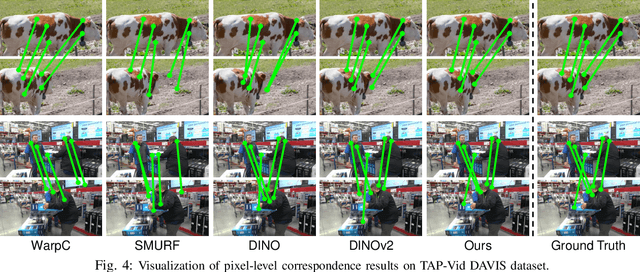
Dense visual correspondence plays a vital role in robotic perception. This work focuses on establishing the dense correspondence between a pair of images that captures dynamic scenes undergoing substantial transformations. We introduce Doduo to learn general dense visual correspondence from in-the-wild images and videos without ground truth supervision. Given a pair of images, it estimates the dense flow field encoding the displacement of each pixel in one image to its corresponding pixel in the other image. Doduo uses flow-based warping to acquire supervisory signals for the training. Incorporating semantic priors with self-supervised flow training, Doduo produces accurate dense correspondence robust to the dynamic changes of the scenes. Trained on an in-the-wild video dataset, Doduo illustrates superior performance on point-level correspondence estimation over existing self-supervised correspondence learning baselines. We also apply Doduo to articulation estimation and zero-shot goal-conditioned manipulation, underlining its practical applications in robotics. Code and additional visualizations are available at https://ut-austin-rpl.github.io/Doduo