 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric scene context for human-centric environment understanding from video
Paper and Code
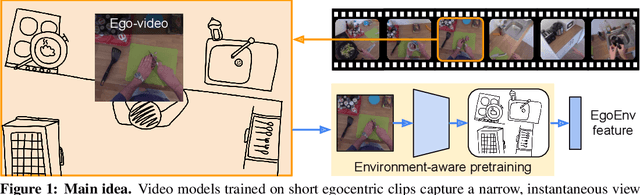
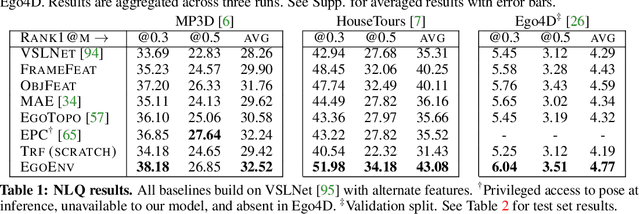
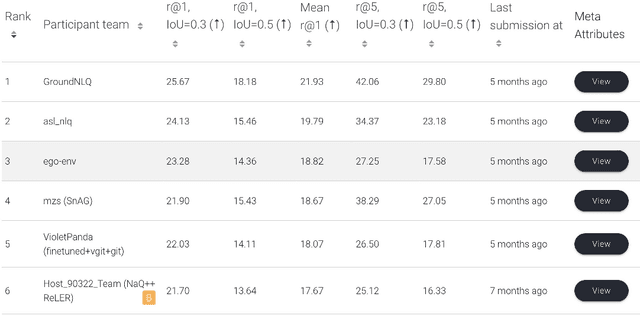
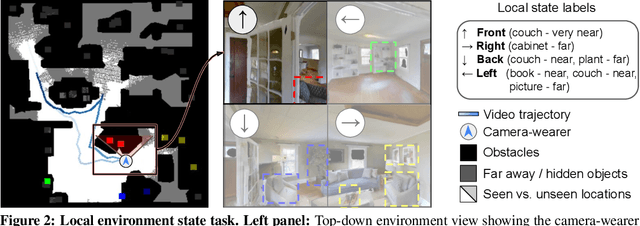
First-person video highlights a camera-wearer's activities in the context of their persistent environment. However, current video understanding approaches reason over visual features from short video clips that are detached from the underlying physical space and only capture what is directly seen. We present an approach that links egocentric video and camera pose over time by learning representations that are predictive of the camera-wearer's (potentially unseen) local surroundings to facilitate human-centric environment understanding. We train such models using videos from agents in simulated 3D environments where the environment is fully observable, and test them on real-world videos of house tours from unseen environments. We show that by grounding videos in their physical environment, our models surpass traditional scene classification models at predicting which room a camera-wearer is in (where frame-level information is insufficient), and can leverage this grounding to localize video moments corresponding to environment-centric queries, outperforming prior methods. Project page: http://vision.cs.utexas.edu/projects/ego-scene-context/