 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Visually Grounded Memory Assistant
Oct 07, 2022


We introduce a novel interface for large scale collection of human memory and assistance. Using the 3D Matterport simulator we create a realistic indoor environments in which we have people perform specific embodied memory tasks that mimic household daily activities. This interface was then deployed on Amazon Mechanical Turk allowing us to test and record human memory, navigation and needs for assistance at a large scale that was previously impossible. Using the interface we collect the `The Visually Grounded Memory Assistant Dataset' which is aimed at developing our understanding of (1) the information people encode during navigation of 3D environments and (2) conditions under which people ask for memory assistance. Additionally we experiment with with predicting when people will ask for assistance using models trained on hand-selected visual and semantic features. This provides an opportunity to build stronger ties between the machine-learning and cognitive-science communities through learned models of human perception, memory, and cognition.
Egocentric scene context for human-centric environment understanding from video
Jul 22, 2022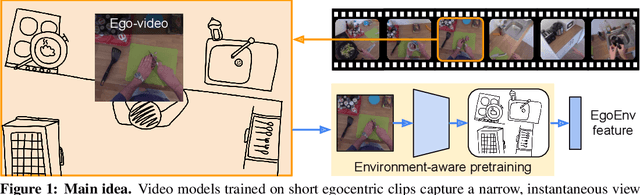
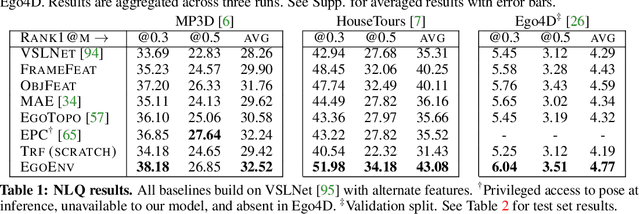
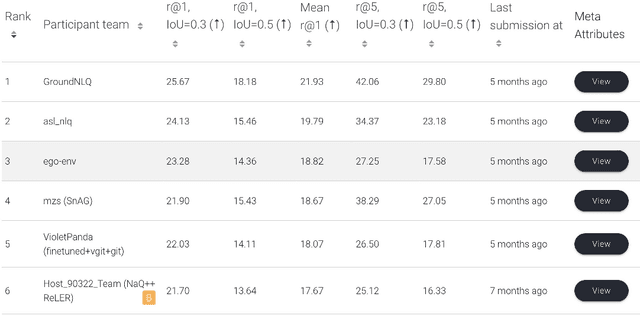
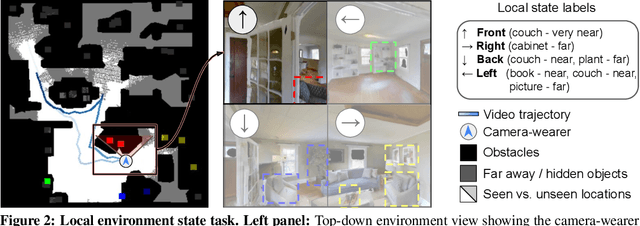
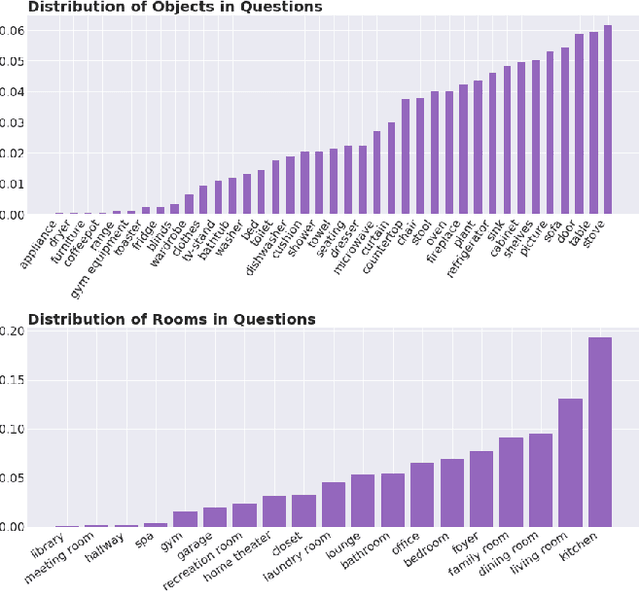
First-person video highlights a camera-wearer's activities in the context of their persistent environment. However, current video understanding approaches reason over visual features from short video clips that are detached from the underlying physical space and only capture what is directly seen. We present an approach that links egocentric video and camera pose over time by learning representations that are predictive of the camera-wearer's (potentially unseen) local surroundings to facilitate human-centric environment understanding. We train such models using videos from agents in simulated 3D environments where the environment is fully observable, and test them on real-world videos of house tours from unseen environments. We show that by grounding videos in their physical environment, our models surpass traditional scene classification models at predicting which room a camera-wearer is in (where frame-level information is insufficient), and can leverage this grounding to localize video moments corresponding to environment-centric queries, outperforming prior methods. Project page: http://vision.cs.utexas.edu/projects/ego-scene-context/
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021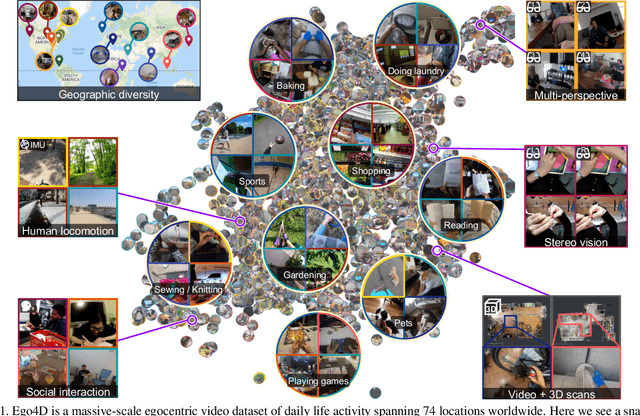
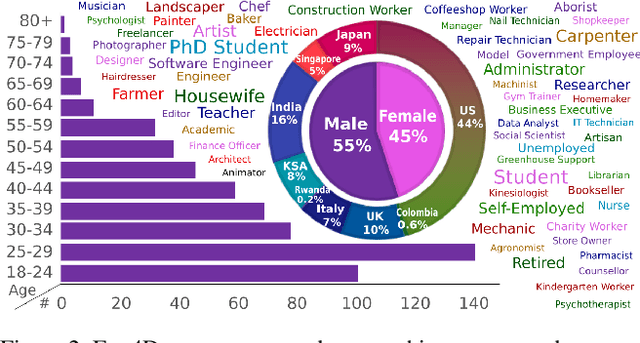

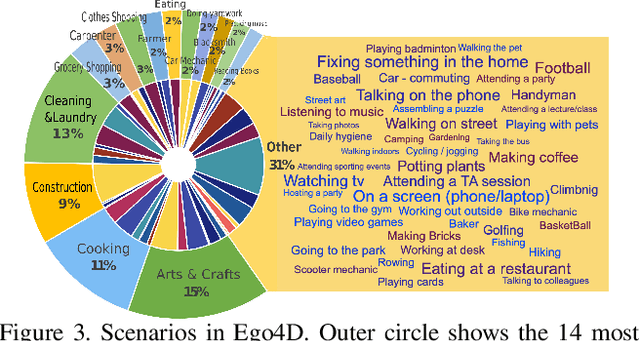
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/