 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePONI: Potential Functions for ObjectGoal Navigation with Interaction-free Learning
Paper and Code
Jan 25, 2022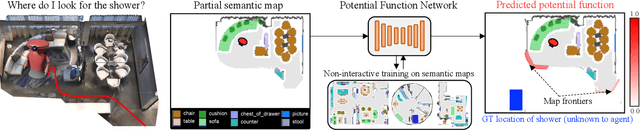
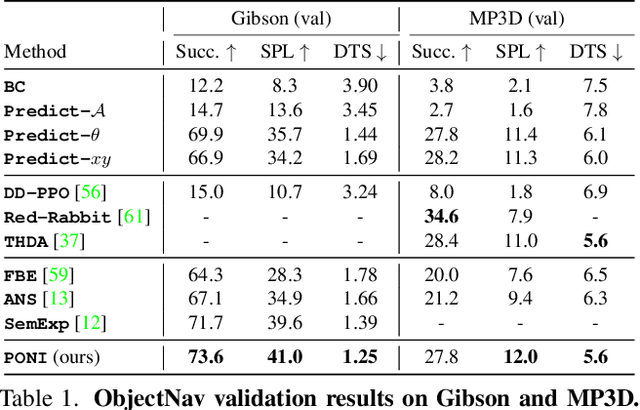
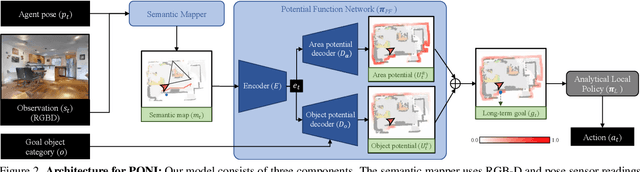
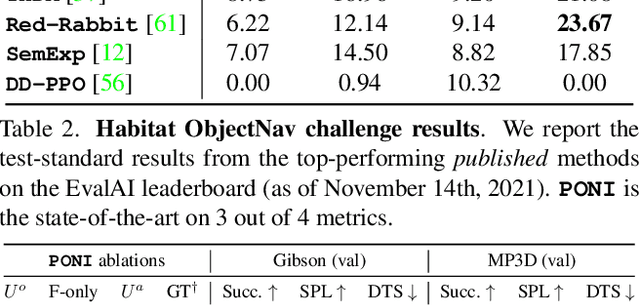
State-of-the-art approaches to ObjectGoal navigation rely on reinforcement learning and typically require significant computational resources and time for learning. We propose Potential functions for ObjectGoal Navigation with Interaction-free learning (PONI), a modular approach that disentangles the skills of `where to look?' for an object and `how to navigate to (x, y)?'. Our key insight is that `where to look?' can be treated purely as a perception problem, and learned without environment interactions. To address this, we propose a network that predicts two complementary potential functions conditioned on a semantic map and uses them to decide where to look for an unseen object. We train the potential function network using supervised learning on a passive dataset of top-down semantic maps, and integrate it into a modular framework to perform ObjectGoal navigation. Experiments on Gibson and Matterport3D demonstrate that our method achieves the state-of-the-art for ObjectGoal navigation while incurring up to 1,600x less computational cost for training.