 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStitch-a-Recipe: Video Demonstration from Multistep Descriptions
Mar 18, 2025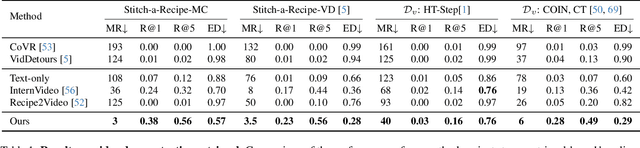
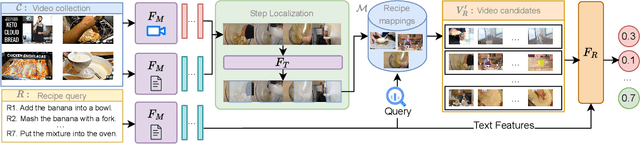
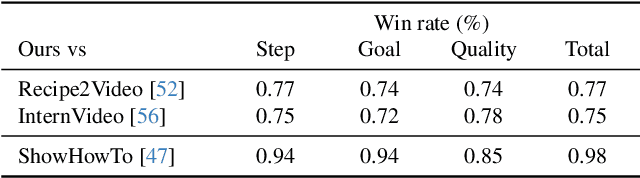

When obtaining visual illustrations from text descriptions, today's methods take a description with-a single text context caption, or an action description-and retrieve or generate the matching visual context. However, prior work does not permit visual illustration of multistep descriptions, e.g. a cooking recipe composed of multiple steps. Furthermore, simply handling each step description in isolation would result in an incoherent demonstration. We propose Stitch-a-Recipe, a novel retrieval-based method to assemble a video demonstration from a multistep description. The resulting video contains clips, possibly from different sources, that accurately reflect all the step descriptions, while being visually coherent. We formulate a training pipeline that creates large-scale weakly supervised data containing diverse and novel recipes and injects hard negatives that promote both correctness and coherence. Validated on in-the-wild instructional videos, Stitch-a-Recipe achieves state-of-the-art performance, with quantitative gains up to 24% as well as dramatic wins in a human preference study.