 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss functions incorporating auditory spatial perception in deep learning -- a review
Jun 24, 2025Binaural reproduction aims to deliver immersive spatial audio with high perceptual realism over headphones. Loss functions play a central role in optimizing and evaluating algorithms that generate binaural signals. However, traditional signal-related difference measures often fail to capture the perceptual properties that are essential to spatial audio quality. This review paper surveys recent loss functions that incorporate spatial perception cues relevant to binaural reproduction. It focuses on losses applied to binaural signals, which are often derived from microphone recordings or Ambisonics signals, while excluding those based on room impulse responses. Guided by the Spatial Audio Quality Inventory (SAQI), the review emphasizes perceptual dimensions related to source localization and room response, while excluding general spectral-temporal attributes. The literature survey reveals a strong focus on localization cues, such as interaural time and level differences (ITDs, ILDs), while reverberation and other room acoustic attributes remain less explored in loss function design. Recent works that estimate room acoustic parameters and develop embeddings that capture room characteristics indicate their potential for future integration into neural network training. The paper concludes by highlighting future research directions toward more perceptually grounded loss functions that better capture the listener's spatial experience.
Ambisonics Binaural Rendering via Masked Magnitude Least Squares
Jan 30, 2025



Ambisonics rendering has become an integral part of 3D audio for headphones. It works well with existing recording hardware, the processing cost is mostly independent of the number of sound sources, and it elegantly allows for rotating the scene and listener. One challenge in Ambisonics headphone rendering is to find a perceptually well behaved low-order representation of the Head-Related Transfer Functions (HRTFs) that are contained in the rendering pipe-line. Low-order rendering is of interest, when working with microphone arrays containing only a few sensors, or for reducing the bandwidth for signal transmission. Magnitude Least Squares rendering became the de facto standard for this, which discards high-frequency interaural phase information in favor of reducing magnitude errors. Building upon this idea, we suggest Masked Magnitude Least Squares, which optimized the Ambisonics coefficients with a neural network and employs a spatio-spectral weighting mask to control the accuracy of the magnitude reconstruction. In the tested case, the weighting mask helped to maintain high-frequency notches in the low-order HRTFs and improved the modeled median plane localization performance in comparison to MagLS, while only marginally affecting the overall accuracy of the magnitude reconstruction.
A Database with Directivities of Musical Instruments
Jul 05, 2023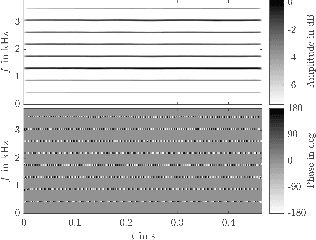


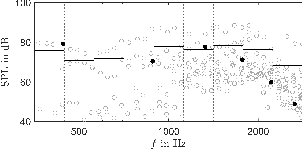
We present a database of recordings and radiation patterns of individual notes for 41 modern and historical musical instruments, measured with a 32-channel spherical microphone array in anechoic conditions. In addition, directivities averaged in one-third octave bands have been calculated for each instrument, which are suitable for use in acoustic simulation and auralisation. The data are provided in SOFA format. Spatial upsampling of the directivities was performed based on spherical spline interpolation and converted to OpenDAFF and GLL format for use in room acoustic and electro-acoustic simulation software. For this purpose, a method is presented how these directivities can be referenced to a specific microphone position in order to achieve a physically correct auralisation without colouration. The data is available under the CC BY-SA 4.0 licence.
Magnitude-Corrected and Time-Aligned Interpolation of Head-Related Transfer Functions
Mar 17, 2023Head-related transfer functions (HRTFs) are essential for virtual acoustic realities, as they contain all cues for localizing sound sources in three-dimensional space. Acoustic measurements are one way to obtain high-quality HRTFs. To reduce measurement time, cost, and complexity of measurement systems, a promising approach is to capture only a few HRTFs on a sparse sampling grid and then upsample them to a dense HRTF set by interpolation. However, HRTF interpolation is challenging because small changes in source position can result in significant changes in the HRTF phase and magnitude response. Previous studies greatly improved the interpolation by time-aligning the HRTFs in preprocessing, but magnitude interpolation errors, especially in contralateral regions, remain a problem. Building upon the time-alignment approaches, we propose an additional post-interpolation magnitude correction derived from a frequency-smoothed HRTF representation. Employing all 96 individual simulated HRTF sets of the HUTUBS database, we show that the magnitude correction significantly reduces interpolation errors compared to state-of-the-art interpolation methods applying only time alignment. Our analysis shows that when upsampling very sparse HRTF sets, the subject-averaged magnitude error in the critical higher frequency range is up to 1.5 dB lower when averaged over all directions and even up to 4 dB lower in the contralateral region. As a result, the interaural level differences in the upsampled HRTFs are considerably improved. The proposed algorithm thus has the potential to further reduce the minimum number of HRTFs required for perceptually transparent interpolation.