 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat You Feel Is Not What They See: On Predicting Self-Reported Emotion from Third-Party Observer Labels
Jan 29, 2026Self-reported emotion labels capture internal experience, while third-party labels reflect external perception. These perspectives often diverge, limiting the applicability of third-party-trained models to self-report contexts. This gap is critical in mental health, where accurate self-report modeling is essential for guiding intervention. We present the first cross-corpus evaluation of third-party-trained models on self-reports. We find activation unpredictable (CCC approximately 0) and valence moderately predictable (CCC approximately 0.3). Crucially, when content is personally significant to the speaker, models achieve high performance for valence (CCC approximately 0.6-0.8). Our findings point to personal significance as a key pathway for aligning external perception with internal experience and underscore the challenge of self-report activation modeling.
Beyond Binary: Multiclass Paraphasia Detection with Generative Pretrained Transformers and End-to-End Models
Jul 16, 2024
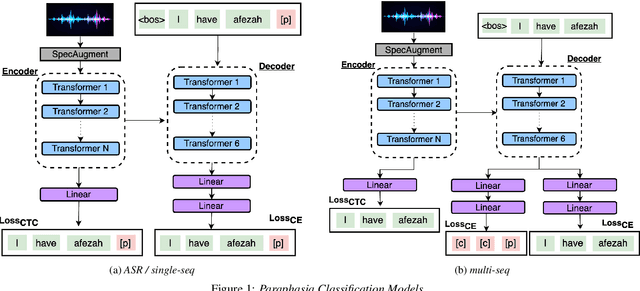
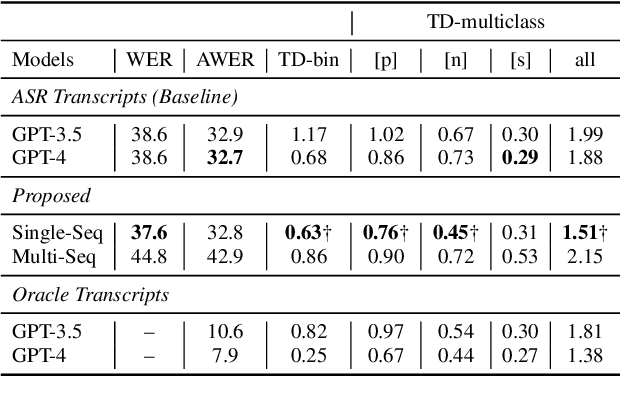
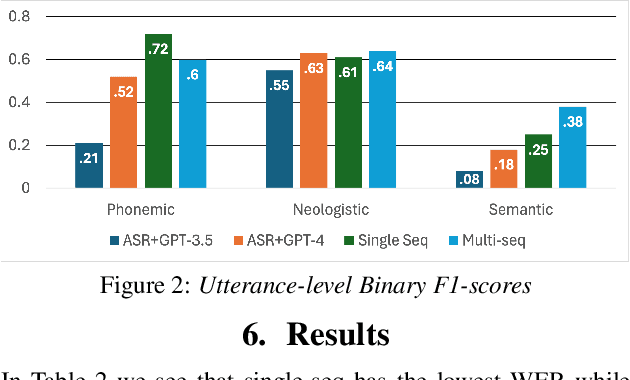
Aphasia is a language disorder that can lead to speech errors known as paraphasias, which involve the misuse, substitution, or invention of words. Automatic paraphasia detection can help those with Aphasia by facilitating clinical assessment and treatment planning options. However, most automatic paraphasia detection works have focused solely on binary detection, which involves recognizing only the presence or absence of a paraphasia. Multiclass paraphasia detection represents an unexplored area of research that focuses on identifying multiple types of paraphasias and where they occur in a given speech segment. We present novel approaches that use a generative pretrained transformer (GPT) to identify paraphasias from transcripts as well as two end-to-end approaches that focus on modeling both automatic speech recognition (ASR) and paraphasia classification as multiple sequences vs. a single sequence. We demonstrate that a single sequence model outperforms GPT baselines for multiclass paraphasia detection.
SeedBERT: Recovering Annotator Rating Distributions from an Aggregated Label
Nov 23, 2022


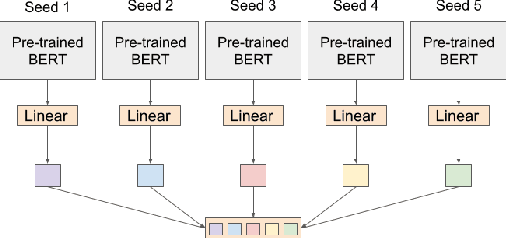
Many machine learning tasks -- particularly those in affective computing -- are inherently subjective. When asked to classify facial expressions or to rate an individual's attractiveness, humans may disagree with one another, and no single answer may be objectively correct. However, machine learning datasets commonly have just one "ground truth" label for each sample, so models trained on these labels may not perform well on tasks that are subjective in nature. Though allowing models to learn from the individual annotators' ratings may help, most datasets do not provide annotator-specific labels for each sample. To address this issue, we propose SeedBERT, a method for recovering annotator rating distributions from a single label by inducing pre-trained models to attend to different portions of the input. Our human evaluations indicate that SeedBERT's attention mechanism is consistent with human sources of annotator disagreement. Moreover, in our empirical evaluations using large language models, SeedBERT demonstrates substantial gains in performance on downstream subjective tasks compared both to standard deep learning models and to other current models that account explicitly for annotator disagreement.