 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Policy Learning through Extrapolation: Application to Pre-trial Risk Assessment
Paper and Code
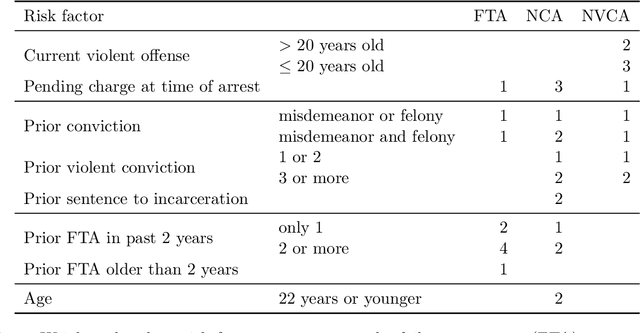
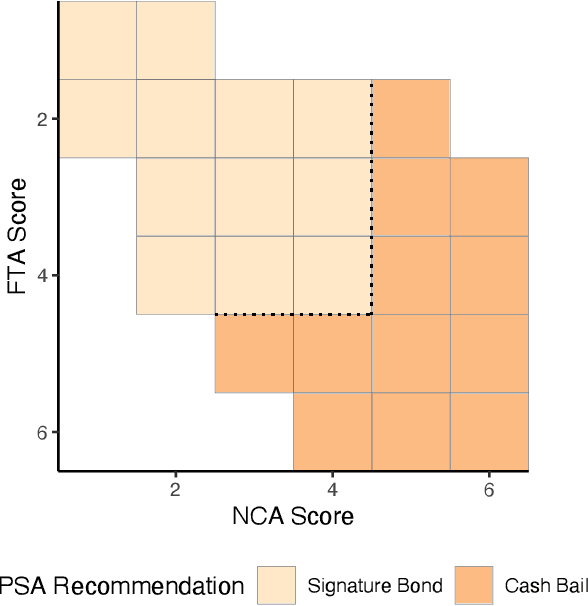

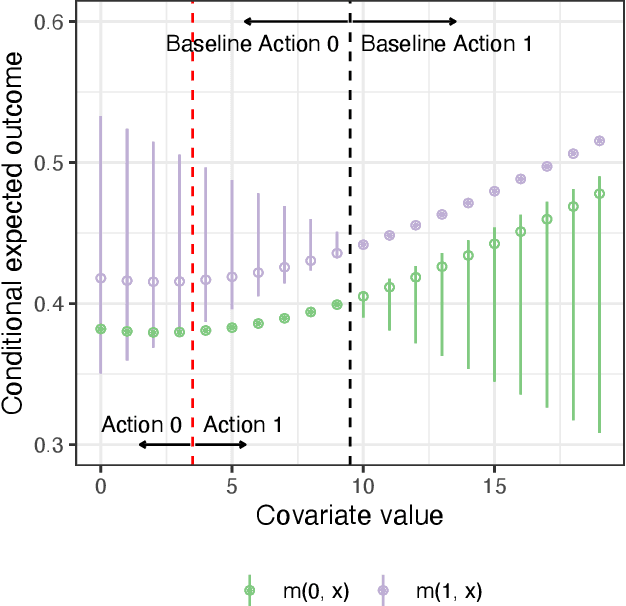
Algorithmic recommendations and decisions have become ubiquitous in today's society. Many of these and other data-driven policies are based on known, deterministic rules to ensure their transparency and interpretability. This is especially true when such policies are used for public policy decision-making. For example, algorithmic pre-trial risk assessments, which serve as our motivating application, provide relatively simple, deterministic classification scores and recommendations to help judges make release decisions. Unfortunately, existing methods for policy learning are not applicable because they require existing policies to be stochastic rather than deterministic. We develop a robust optimization approach that partially identifies the expected utility of a policy, and then finds an optimal policy by minimizing the worst-case regret. The resulting policy is conservative but has a statistical safety guarantee, allowing the policy-maker to limit the probability of producing a worse outcome than the existing policy. We extend this approach to common and important settings where humans make decisions with the aid of algorithmic recommendations. Lastly, we apply the proposed methodology to a unique field experiment on pre-trial risk assessments. We derive new classification and recommendation rules that retain the transparency and interpretability of the existing risk assessment instrument while potentially leading to better overall outcomes at a lower cost.