 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Sparsification via Stimulative Training
Paper and Code
Mar 11, 2024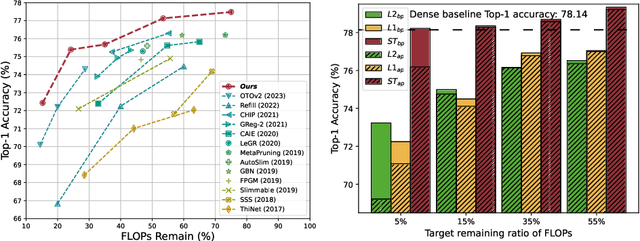

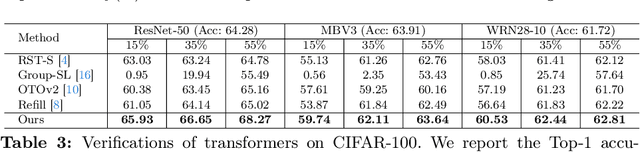
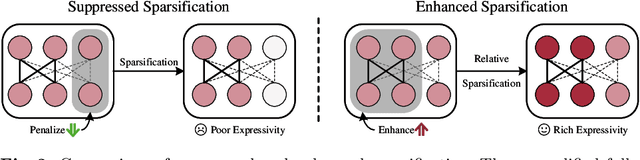
Sparsification-based pruning has been an important category in model compression. Existing methods commonly set sparsity-inducing penalty terms to suppress the importance of dropped weights, which is regarded as the suppressed sparsification paradigm. However, this paradigm inactivates the dropped parts of networks causing capacity damage before pruning, thereby leading to performance degradation. To alleviate this issue, we first study and reveal the relative sparsity effect in emerging stimulative training and then propose a structured pruning framework, named STP, based on an enhanced sparsification paradigm which maintains the magnitude of dropped weights and enhances the expressivity of kept weights by self-distillation. Besides, to find an optimal architecture for the pruned network, we propose a multi-dimension architecture space and a knowledge distillation-guided exploration strategy. To reduce the huge capacity gap of distillation, we propose a subnet mutating expansion technique. Extensive experiments on various benchmarks indicate the effectiveness of STP. Specifically, without fine-tuning, our method consistently achieves superior performance at different budgets, especially under extremely aggressive pruning scenarios, e.g., remaining 95.11% Top-1 accuracy (72.43% in 76.15%) while reducing 85% FLOPs for ResNet-50 on ImageNet. Codes will be released soon.