 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Gemini-3-Pro: Revisiting LLM Routing and Aggregation at Scale
Jan 04, 2026Large Language Models (LLMs) have rapidly advanced, with Gemini-3-Pro setting a new performance milestone. In this work, we explore collective intelligence as an alternative to monolithic scaling, and demonstrate that open-source LLMs' collaboration can surpass Gemini-3-Pro. We first revisit LLM routing and aggregation at scale and identify three key bottlenecks: (1) current train-free routers are limited by a query-based paradigm focusing solely on textual similarity; (2) recent aggregation methods remain largely static, failing to select appropriate aggregators for different tasks;(3) the complementarity of routing and aggregation remains underutilized. To address these problems, we introduce JiSi, a novel framework designed to release the full potential of LLMs' collaboration through three innovations: (1) Query-Response Mixed Routing capturing both semantic information and problem difficulty; (2) Support-Set-based Aggregator Selection jointly evaluating the aggregation and domain capacity of aggregators; (3) Adaptive Routing-Aggregation Switch dynamically leveraging the advantages of routing and aggregation. Comprehensive experiments on nine benchmarks demonstrate that JiSi can surpass Gemini-3-Pro with only 47% costs by orchestrating ten open-source LLMs, while outperforming mainstream baselines. It suggests that collective intelligence represents a novel path towards Artificial General Intelligence (AGI).
Wisdom of the Crowd: Reinforcement Learning from Coevolutionary Collective Feedback
Aug 17, 2025



Reinforcement learning (RL) has significantly enhanced the reasoning capabilities of large language models (LLMs), but its reliance on expensive human-labeled data or complex reward models severely limits scalability. While existing self-feedback methods aim to address this problem, they are constrained by the capabilities of a single model, which can lead to overconfidence in incorrect answers, reward hacking, and even training collapse. To this end, we propose Reinforcement Learning from Coevolutionary Collective Feedback (RLCCF), a novel RL framework that enables multi-model collaborative evolution without external supervision. Specifically, RLCCF optimizes the ability of a model collective by maximizing its Collective Consistency (CC), which jointly trains a diverse ensemble of LLMs and provides reward signals by voting on collective outputs. Moreover, each model's vote is weighted by its Self-Consistency (SC) score, ensuring that more confident models contribute more to the collective decision. Benefiting from the diverse output distributions and complementary abilities of multiple LLMs, RLCCF enables the model collective to continuously enhance its reasoning ability through coevolution. Experiments on four mainstream open-source LLMs across four mathematical reasoning benchmarks demonstrate that our framework yields significant performance gains, achieving an average relative improvement of 16.72\% in accuracy. Notably, RLCCF not only improves the performance of individual models but also enhances the group's majority-voting accuracy by 4.51\%, demonstrating its ability to extend the collective capability boundary of the model collective.
Multi-Level Decoupled Relational Distillation for Heterogeneous Architectures
Feb 10, 2025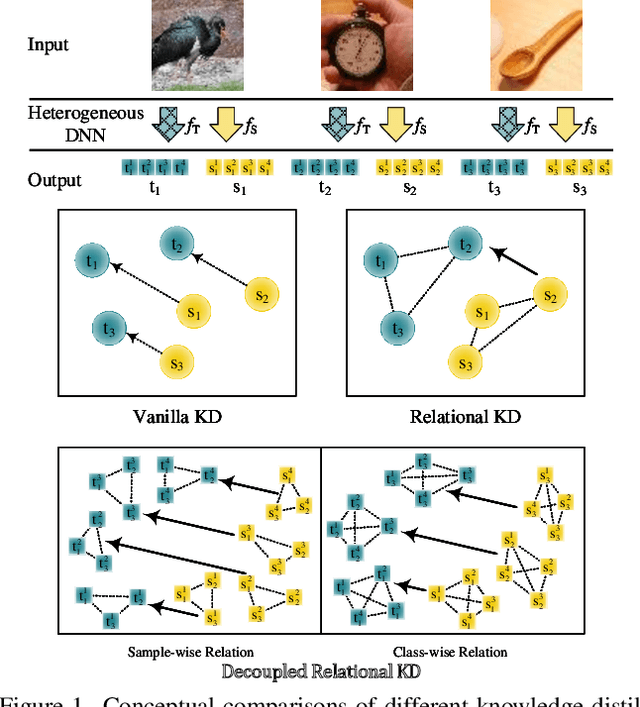
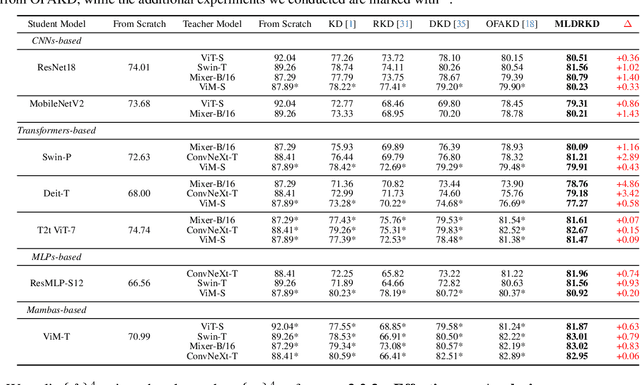

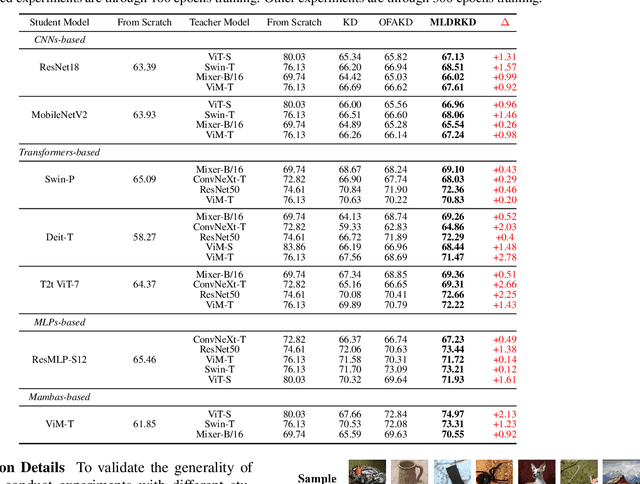
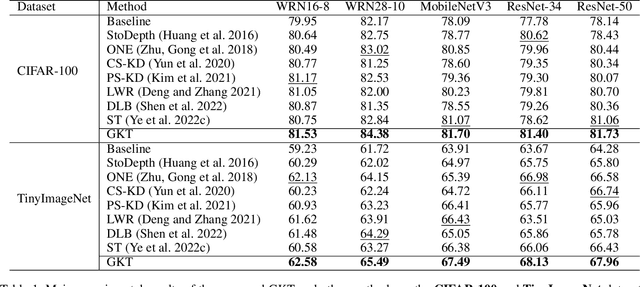
Heterogeneous distillation is an effective way to transfer knowledge from cross-architecture teacher models to student models. However, existing heterogeneous distillation methods do not take full advantage of the dark knowledge hidden in the teacher's output, limiting their performance.To this end, we propose a novel framework named Multi-Level Decoupled Relational Knowledge Distillation (MLDR-KD) to unleash the potential of relational distillation in heterogeneous distillation. Concretely, we first introduce Decoupled Finegrained Relation Alignment (DFRA) in both logit and feature levels to balance the trade-off between distilled dark knowledge and the confidence in the correct category of the heterogeneous teacher model. Then, Multi-Scale Dynamic Fusion (MSDF) module is applied to dynamically fuse the projected logits of multiscale features at different stages in student model, further improving performance of our method in feature level. We verify our method on four architectures (CNNs, Transformers, MLPs and Mambas), two datasets (CIFAR-100 and Tiny-ImageNet). Compared with the best available method, our MLDR-KD improves student model performance with gains of up to 4.86% on CIFAR-100 and 2.78% on Tiny-ImageNet datasets respectively, showing robustness and generality in heterogeneous distillation. Code will be released soon.
S2HPruner: Soft-to-Hard Distillation Bridges the Discretization Gap in Pruning
Oct 09, 2024Recently, differentiable mask pruning methods optimize the continuous relaxation architecture (soft network) as the proxy of the pruned discrete network (hard network) for superior sub-architecture search. However, due to the agnostic impact of the discretization process, the hard network struggles with the equivalent representational capacity as the soft network, namely discretization gap, which severely spoils the pruning performance. In this paper, we first investigate the discretization gap and propose a novel structural differentiable mask pruning framework named S2HPruner to bridge the discretization gap in a one-stage manner. In the training procedure, SH2Pruner forwards both the soft network and its corresponding hard network, then distills the hard network under the supervision of the soft network. To optimize the mask and prevent performance degradation, we propose a decoupled bidirectional knowledge distillation. It blocks the weight updating from the hard to the soft network while maintaining the gradient corresponding to the mask. Compared with existing pruning arts, S2HPruner achieves surpassing pruning performance without fine-tuning on comprehensive benchmarks, including CIFAR-100, Tiny ImageNet, and ImageNet with a variety of network architectures. Besides, investigation and analysis experiments explain the effectiveness of S2HPruner. Codes will be released soon.
HiSplat: Hierarchical 3D Gaussian Splatting for Generalizable Sparse-View Reconstruction
Oct 08, 2024



Reconstructing 3D scenes from multiple viewpoints is a fundamental task in stereo vision. Recently, advances in generalizable 3D Gaussian Splatting have enabled high-quality novel view synthesis for unseen scenes from sparse input views by feed-forward predicting per-pixel Gaussian parameters without extra optimization. However, existing methods typically generate single-scale 3D Gaussians, which lack representation of both large-scale structure and texture details, resulting in mislocation and artefacts. In this paper, we propose a novel framework, HiSplat, which introduces a hierarchical manner in generalizable 3D Gaussian Splatting to construct hierarchical 3D Gaussians via a coarse-to-fine strategy. Specifically, HiSplat generates large coarse-grained Gaussians to capture large-scale structures, followed by fine-grained Gaussians to enhance delicate texture details. To promote inter-scale interactions, we propose an Error Aware Module for Gaussian compensation and a Modulating Fusion Module for Gaussian repair. Our method achieves joint optimization of hierarchical representations, allowing for novel view synthesis using only two-view reference images. Comprehensive experiments on various datasets demonstrate that HiSplat significantly enhances reconstruction quality and cross-dataset generalization compared to prior single-scale methods. The corresponding ablation study and analysis of different-scale 3D Gaussians reveal the mechanism behind the effectiveness. Project website: https://open3dvlab.github.io/HiSplat/
Enhanced Sparsification via Stimulative Training
Mar 11, 2024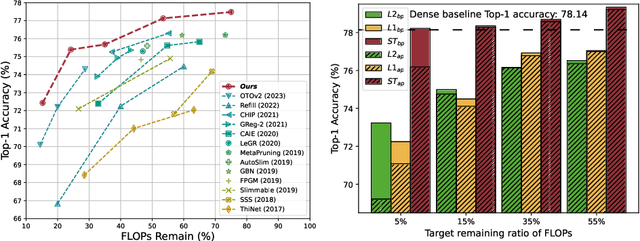

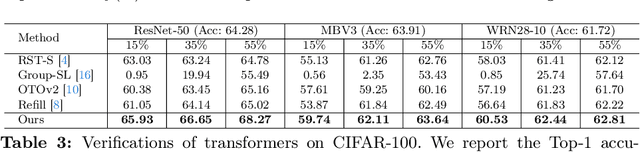
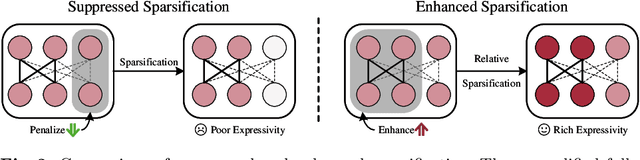
Sparsification-based pruning has been an important category in model compression. Existing methods commonly set sparsity-inducing penalty terms to suppress the importance of dropped weights, which is regarded as the suppressed sparsification paradigm. However, this paradigm inactivates the dropped parts of networks causing capacity damage before pruning, thereby leading to performance degradation. To alleviate this issue, we first study and reveal the relative sparsity effect in emerging stimulative training and then propose a structured pruning framework, named STP, based on an enhanced sparsification paradigm which maintains the magnitude of dropped weights and enhances the expressivity of kept weights by self-distillation. Besides, to find an optimal architecture for the pruned network, we propose a multi-dimension architecture space and a knowledge distillation-guided exploration strategy. To reduce the huge capacity gap of distillation, we propose a subnet mutating expansion technique. Extensive experiments on various benchmarks indicate the effectiveness of STP. Specifically, without fine-tuning, our method consistently achieves superior performance at different budgets, especially under extremely aggressive pruning scenarios, e.g., remaining 95.11% Top-1 accuracy (72.43% in 76.15%) while reducing 85% FLOPs for ResNet-50 on ImageNet. Codes will be released soon.
Efficient Architecture Search via Bi-level Data Pruning
Dec 21, 2023Improving the efficiency of Neural Architecture Search (NAS) is a challenging but significant task that has received much attention. Previous works mainly adopted the Differentiable Architecture Search (DARTS) and improved its search strategies or modules to enhance search efficiency. Recently, some methods have started considering data reduction for speedup, but they are not tightly coupled with the architecture search process, resulting in sub-optimal performance. To this end, this work pioneers an exploration into the critical role of dataset characteristics for DARTS bi-level optimization, and then proposes a novel Bi-level Data Pruning (BDP) paradigm that targets the weights and architecture levels of DARTS to enhance efficiency from a data perspective. Specifically, we introduce a new progressive data pruning strategy that utilizes supernet prediction dynamics as the metric, to gradually prune unsuitable samples for DARTS during the search. An effective automatic class balance constraint is also integrated into BDP, to suppress potential class imbalances resulting from data-efficient algorithms. Comprehensive evaluations on the NAS-Bench-201 search space, DARTS search space, and MobileNet-like search space validate that BDP reduces search costs by over 50% while achieving superior performance when applied to baseline DARTS. Besides, we demonstrate that BDP can harmoniously integrate with advanced DARTS variants, like PC-DARTS and \b{eta}-DARTS, offering an approximately 2 times speedup with minimal performance compromises.
SpVOS: Efficient Video Object Segmentation with Triple Sparse Convolution
Oct 23, 2023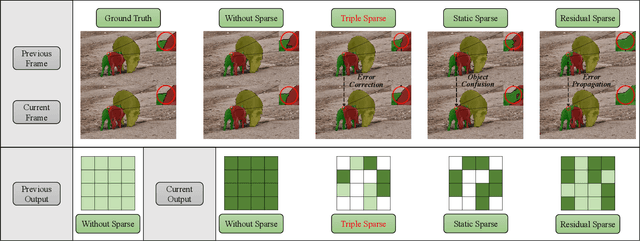
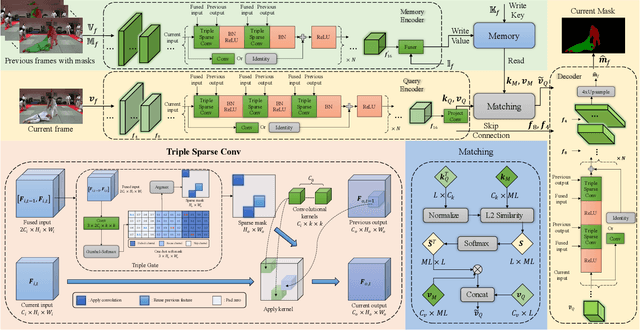
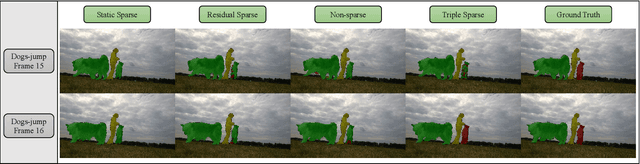
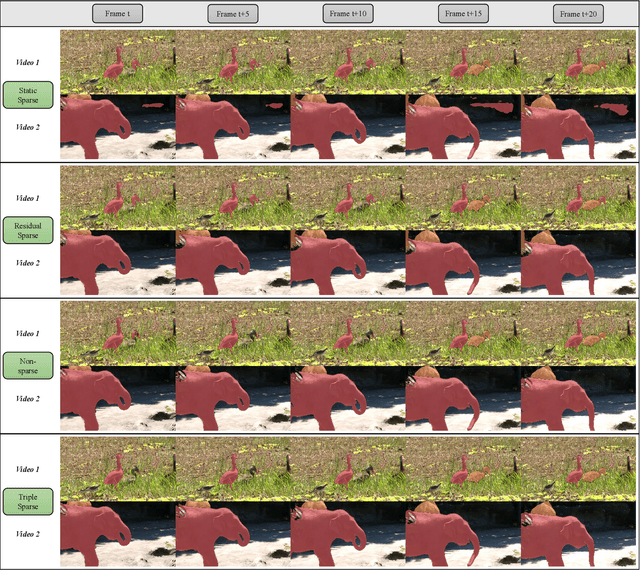
Semi-supervised video object segmentation (Semi-VOS), which requires only annotating the first frame of a video to segment future frames, has received increased attention recently. Among existing pipelines, the memory-matching-based one is becoming the main research stream, as it can fully utilize the temporal sequence information to obtain high-quality segmentation results. Even though this type of method has achieved promising performance, the overall framework still suffers from heavy computation overhead, mainly caused by the per-frame dense convolution operations between high-resolution feature maps and each kernel filter. Therefore, we propose a sparse baseline of VOS named SpVOS in this work, which develops a novel triple sparse convolution to reduce the computation costs of the overall VOS framework. The designed triple gate, taking full consideration of both spatial and temporal redundancy between adjacent video frames, adaptively makes a triple decision to decide how to apply the sparse convolution on each pixel to control the computation overhead of each layer, while maintaining sufficient discrimination capability to distinguish similar objects and avoid error accumulation. A mixed sparse training strategy, coupled with a designed objective considering the sparsity constraint, is also developed to balance the VOS segmentation performance and computation costs. Experiments are conducted on two mainstream VOS datasets, including DAVIS and Youtube-VOS. Results show that, the proposed SpVOS achieves superior performance over other state-of-the-art sparse methods, and even maintains comparable performance, e.g., an 83.04% (79.29%) overall score on the DAVIS-2017 (Youtube-VOS) validation set, with the typical non-sparse VOS baseline (82.88% for DAVIS-2017 and 80.36% for Youtube-VOS) while saving up to 42% FLOPs, showing its application potential for resource-constrained scenarios.
Boosting Residual Networks with Group Knowledge
Aug 26, 2023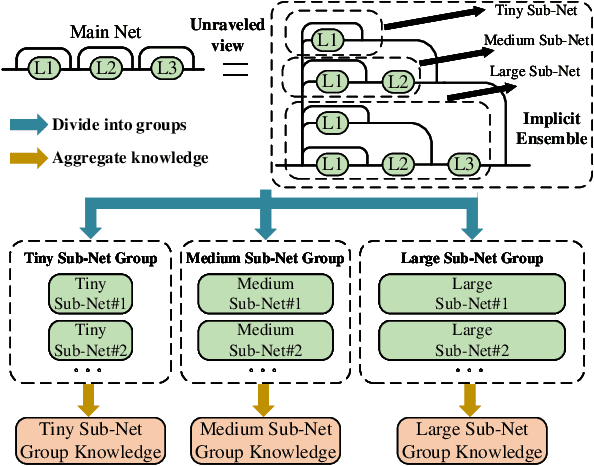
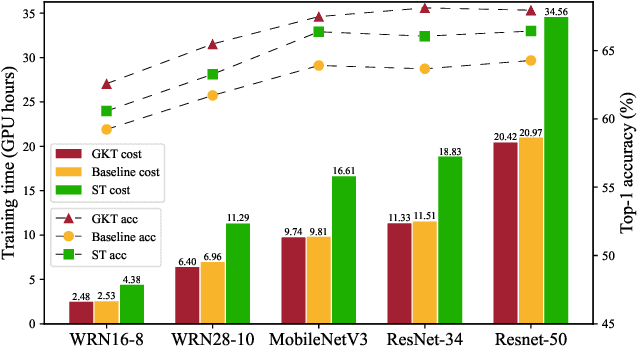
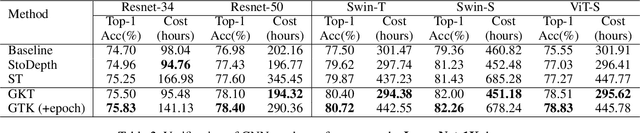
Recent research understands the residual networks from a new perspective of the implicit ensemble model. From this view, previous methods such as stochastic depth and stimulative training have further improved the performance of the residual network by sampling and training of its subnets. However, they both use the same supervision for all subnets of different capacities and neglect the valuable knowledge generated by subnets during training. In this manuscript, we mitigate the significant knowledge distillation gap caused by using the same kind of supervision and advocate leveraging the subnets to provide diverse knowledge. Based on this motivation, we propose a group knowledge based training framework for boosting the performance of residual networks. Specifically, we implicitly divide all subnets into hierarchical groups by subnet-in-subnet sampling, aggregate the knowledge of different subnets in each group during training, and exploit upper-level group knowledge to supervise lower-level subnet groups. Meanwhile, We also develop a subnet sampling strategy that naturally samples larger subnets, which are found to be more helpful than smaller subnets in boosting performance for hierarchical groups. Compared with typical subnet training and other methods, our method achieves the best efficiency and performance trade-offs on multiple datasets and network structures. The code will be released soon.