 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpVOS: Efficient Video Object Segmentation with Triple Sparse Convolution
Paper and Code
Oct 23, 2023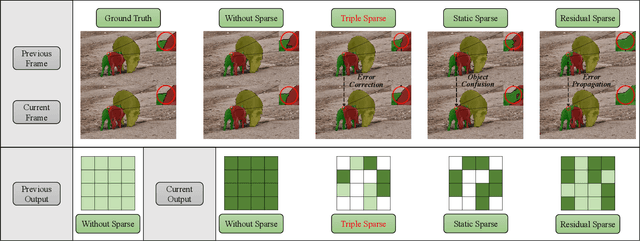
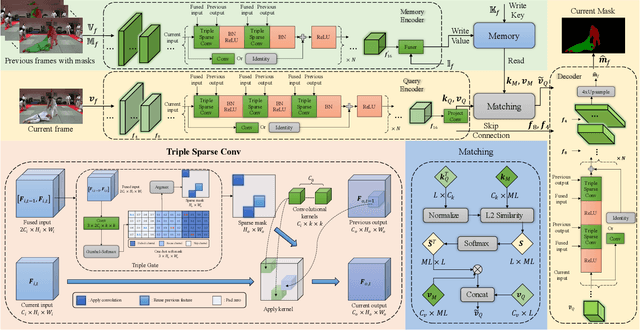
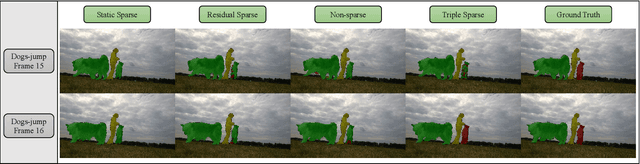
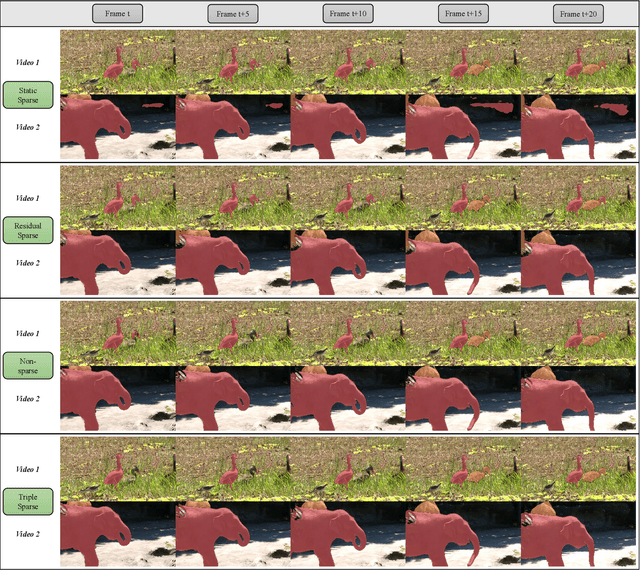
Semi-supervised video object segmentation (Semi-VOS), which requires only annotating the first frame of a video to segment future frames, has received increased attention recently. Among existing pipelines, the memory-matching-based one is becoming the main research stream, as it can fully utilize the temporal sequence information to obtain high-quality segmentation results. Even though this type of method has achieved promising performance, the overall framework still suffers from heavy computation overhead, mainly caused by the per-frame dense convolution operations between high-resolution feature maps and each kernel filter. Therefore, we propose a sparse baseline of VOS named SpVOS in this work, which develops a novel triple sparse convolution to reduce the computation costs of the overall VOS framework. The designed triple gate, taking full consideration of both spatial and temporal redundancy between adjacent video frames, adaptively makes a triple decision to decide how to apply the sparse convolution on each pixel to control the computation overhead of each layer, while maintaining sufficient discrimination capability to distinguish similar objects and avoid error accumulation. A mixed sparse training strategy, coupled with a designed objective considering the sparsity constraint, is also developed to balance the VOS segmentation performance and computation costs. Experiments are conducted on two mainstream VOS datasets, including DAVIS and Youtube-VOS. Results show that, the proposed SpVOS achieves superior performance over other state-of-the-art sparse methods, and even maintains comparable performance, e.g., an 83.04% (79.29%) overall score on the DAVIS-2017 (Youtube-VOS) validation set, with the typical non-sparse VOS baseline (82.88% for DAVIS-2017 and 80.36% for Youtube-VOS) while saving up to 42% FLOPs, showing its application potential for resource-constrained scenarios.