 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional set generation using Seq2seq models
Paper and Code
May 25, 2022
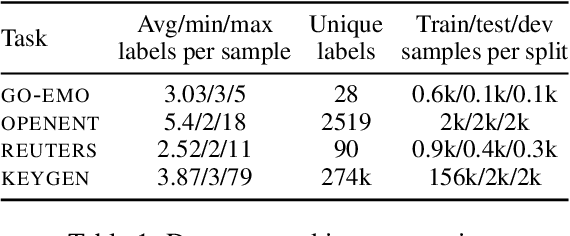
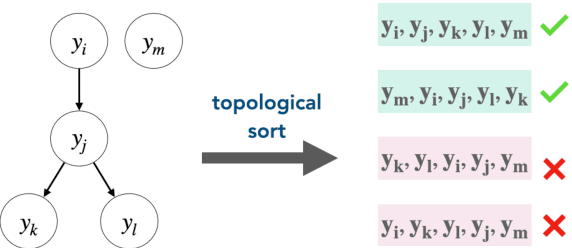
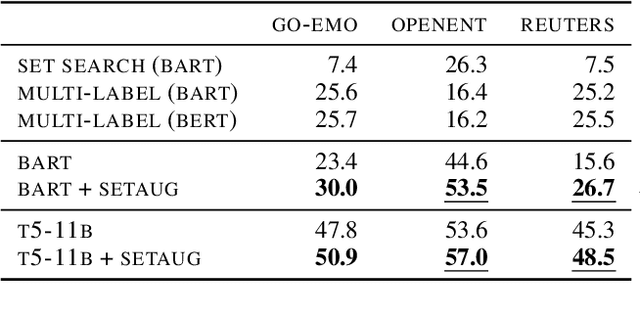
Conditional set generation learns a mapping from an input sequence of tokens to a set. Several NLP tasks, such as entity typing and dialogue emotion tagging, are instances of set generation. Sequence-to-sequence~(Seq2seq) models are a popular choice to model set generation, but they treat a set as a sequence and do not fully leverage its key properties, namely order-invariance and cardinality. We propose a novel algorithm for effectively sampling informative orders over the combinatorial space of label orders. Further, we jointly model the set cardinality and output by adding the set size as the first element and taking advantage of the autoregressive factorization used by Seq2seq models. Our method is a model-independent data augmentation approach that endows any Seq2seq model with the signals of order-invariance and cardinality. Training a Seq2seq model on this new augmented data~(without any additional annotations) gets an average relative improvement of 20% for four benchmarks datasets across models spanning from BART-base, T5-xxl, and GPT-3.