 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniBind: Teach to Build Unequal-Scale Modality Interaction for Omni-Bind of All
Paper and Code
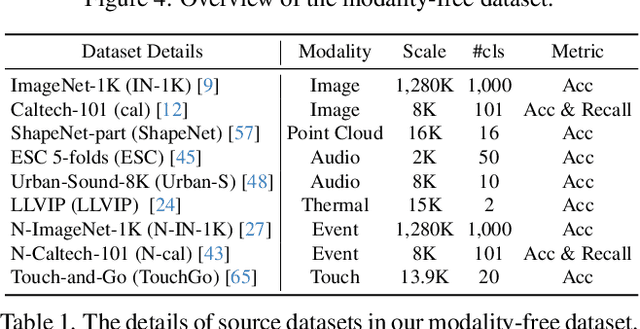
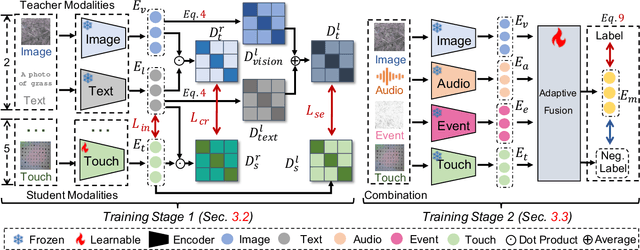
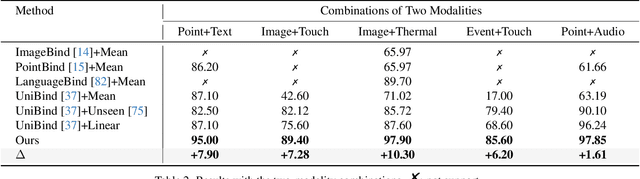
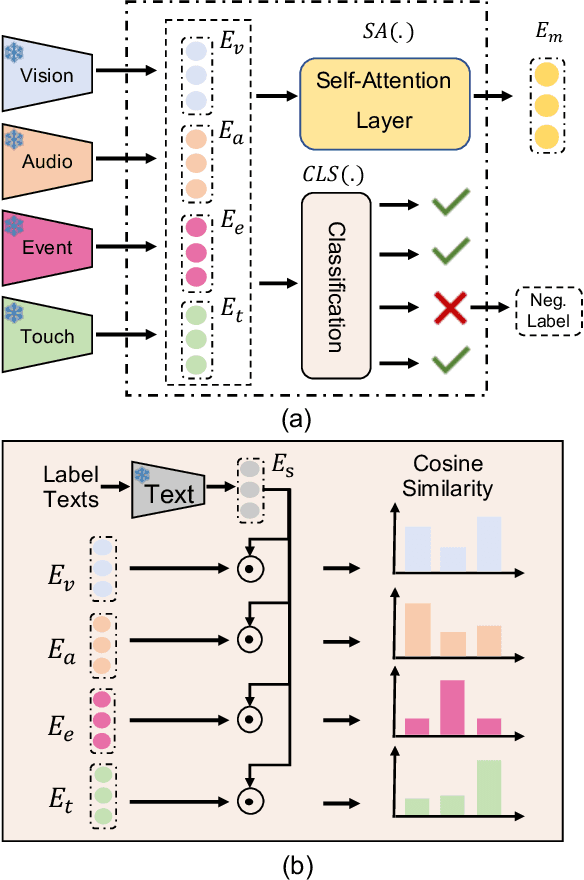
Research on multi-modal learning dominantly aligns the modalities in a unified space at training, and only a single one is taken for prediction at inference. However, for a real machine, e.g., a robot, sensors could be added or removed at any time. Thus, it is crucial to enable the machine to tackle the mismatch and unequal-scale problems of modality combinations between training and inference. In this paper, we tackle these problems from a new perspective: "Modalities Help Modalities". Intuitively, we present OmniBind, a novel two-stage learning framework that can achieve any modality combinations and interaction. It involves teaching data-constrained, a.k.a, student, modalities to be aligned with the well-trained data-abundant, a.k.a, teacher, modalities. This subtly enables the adaptive fusion of any modalities to build a unified representation space for any combinations. Specifically, we propose Cross-modal Alignment Distillation (CAD) to address the unequal-scale problem between student and teacher modalities and effectively align student modalities into the teacher modalities' representation space in stage one. We then propose an Adaptive Fusion (AF) module to fuse any modality combinations and learn a unified representation space in stage two. To address the mismatch problem, we aggregate existing datasets and combine samples from different modalities by the same semantics. This way, we build the first dataset for training and evaluation that consists of teacher (image, text) and student (touch, thermal, event, point cloud, audio) modalities and enables omni-bind for any of them. Extensive experiments on the recognition task show performance gains over prior arts by an average of 4.05 % on the arbitrary modality combination setting. It also achieves state-of-the-art performance for a single modality, e.g., touch, with a 4.34 % gain.