 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREMIND Your Neural Network to Prevent Catastrophic Forgetting
Paper and Code
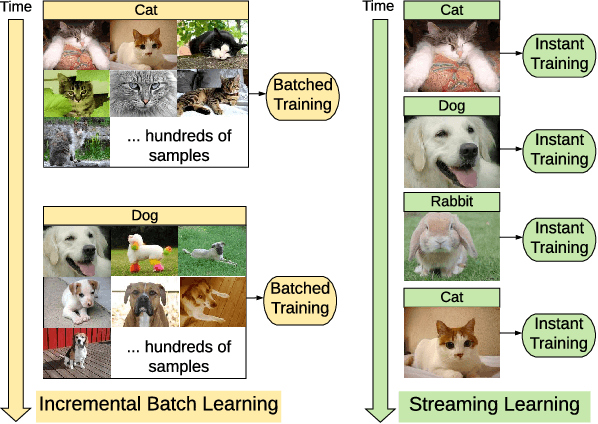
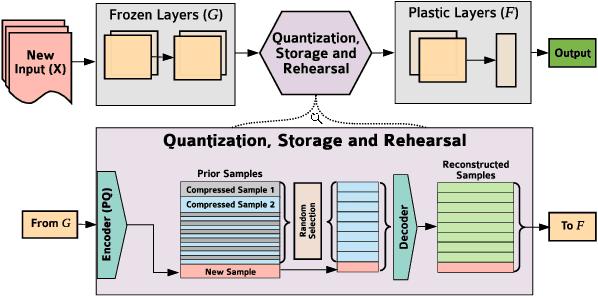
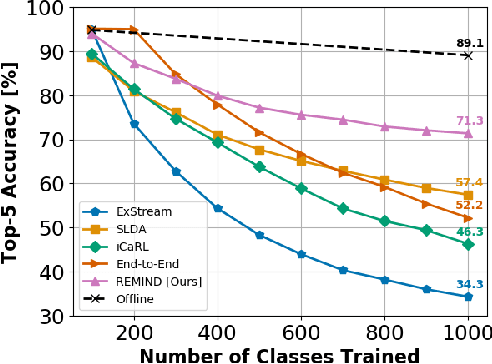
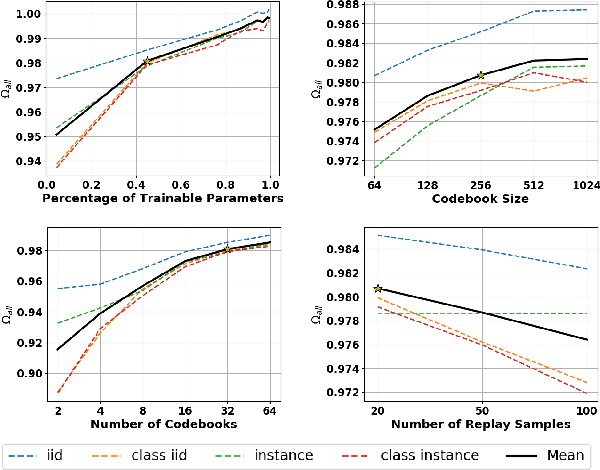
In lifelong machine learning, a robotic agent must be incrementally updated with new knowledge, instead of having distinct train and deployment phases. Conventional neural networks are often used for interpreting sensor data, however, if they are updated on non-stationary data streams, they suffer from catastrophic forgetting, with new learning overwriting past knowledge. A common remedy is replay, which involves mixing old examples with new ones. For incrementally training convolutional neural network models, prior work has enabled replay by storing raw images, but this is memory intensive and not ideal for embedded agents. Here, we propose REMIND, a tensor quantization approach that enables efficient replay with tensors. Unlike other methods, REMIND is trained in a streaming manner, meaning it learns one example at a time rather than in large batches containing multiple classes. Our approach achieves state-of-the-art results for incremental class learning on the ImageNet-1K dataset. We also probe REMIND's robustness to different data ordering schemes using the CORe50 streaming dataset. We demonstrate REMIND's generality by pioneering multi-modal incremental learning for visual question answering (VQA), which cannot be readily done with comparison models. We establish strong baselines on the CLEVR and TDIUC datasets for VQA. The generality of REMIND for multi-modal tasks can enable robotic agents to learn about their visual environment using natural language understanding in an interactive way.