 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Landscape Geometry and the Learning of Symmetries: Or, What Influence Functions Reveal About Robust Generalization
Jan 28, 2026We study how neural emulators of partial differential equation solution operators internalize physical symmetries by introducing an influence-based diagnostic that measures the propagation of parameter updates between symmetry-related states, defined as the metric-weighted overlap of loss gradients evaluated along group orbits. This quantity probes the local geometry of the learned loss landscape and goes beyond forward-pass equivariance tests by directly assessing whether learning dynamics couple physically equivalent configurations. Applying our diagnostic to autoregressive fluid flow emulators, we show that orbit-wise gradient coherence provides the mechanism for learning to generalize over symmetry transformations and indicates when training selects a symmetry compatible basin. The result is a novel technique for evaluating if surrogate models have internalized symmetry properties of the known solution operator.
Low-Rank Learning by Design: the Role of Network Architecture and Activation Linearity in Gradient Rank Collapse
Feb 09, 2024
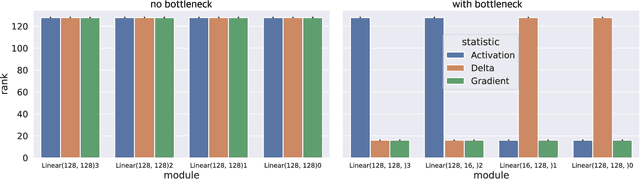

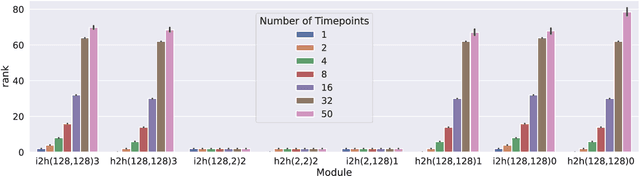
Our understanding of learning dynamics of deep neural networks (DNNs) remains incomplete. Recent research has begun to uncover the mathematical principles underlying these networks, including the phenomenon of "Neural Collapse", where linear classifiers within DNNs converge to specific geometrical structures during late-stage training. However, the role of geometric constraints in learning extends beyond this terminal phase. For instance, gradients in fully-connected layers naturally develop a low-rank structure due to the accumulation of rank-one outer products over a training batch. Despite the attention given to methods that exploit this structure for memory saving or regularization, the emergence of low-rank learning as an inherent aspect of certain DNN architectures has been under-explored. In this paper, we conduct a comprehensive study of gradient rank in DNNs, examining how architectural choices and structure of the data effect gradient rank bounds. Our theoretical analysis provides these bounds for training fully-connected, recurrent, and convolutional neural networks. We also demonstrate, both theoretically and empirically, how design choices like activation function linearity, bottleneck layer introduction, convolutional stride, and sequence truncation influence these bounds. Our findings not only contribute to the understanding of learning dynamics in DNNs, but also provide practical guidance for deep learning engineers to make informed design decisions.
CommsVAE: Learning the brain's macroscale communication dynamics using coupled sequential VAEs
Oct 07, 2022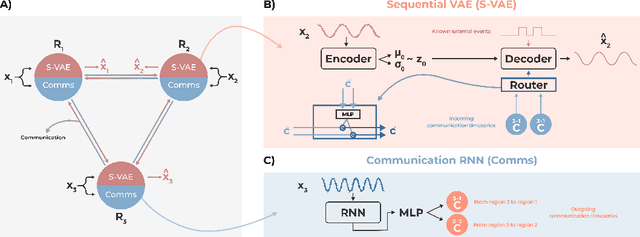
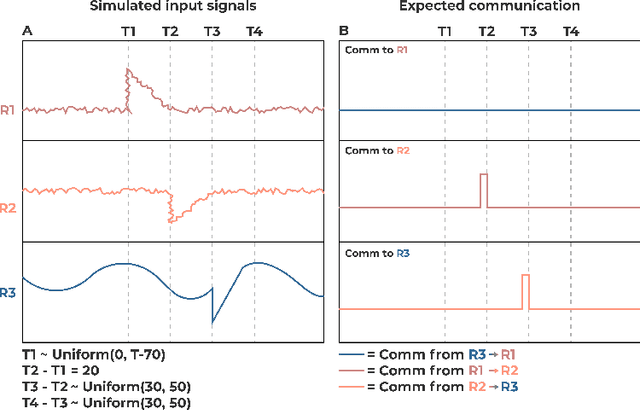
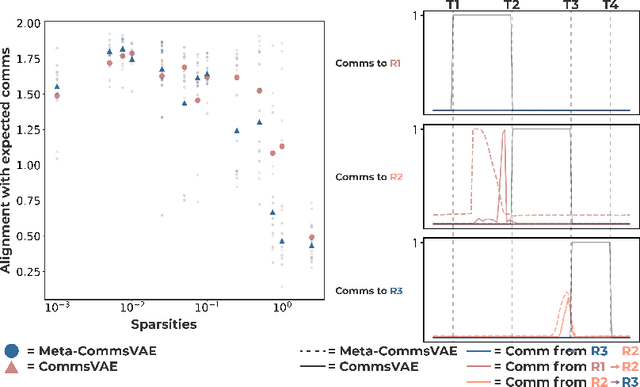
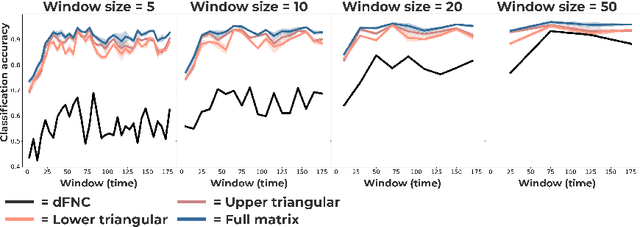
Communication within or between complex systems is commonplace in the natural sciences and fields such as graph neural networks. The brain is a perfect example of such a complex system, where communication between brain regions is constantly being orchestrated. To analyze communication, the brain is often split up into anatomical regions that each perform certain computations. These regions must interact and communicate with each other to perform tasks and support higher-level cognition. On a macroscale, these regions communicate through signal propagation along the cortex and along white matter tracts over longer distances. When and what types of signals are communicated over time is an unsolved problem and is often studied using either functional or structural data. In this paper, we propose a non-linear generative approach to communication from functional data. We address three issues with common connectivity approaches by explicitly modeling the directionality of communication, finding communication at each timestep, and encouraging sparsity. To evaluate our model, we simulate temporal data that has sparse communication between nodes embedded in it and show that our model can uncover the expected communication dynamics. Subsequently, we apply our model to temporal neural data from multiple tasks and show that our approach models communication that is more specific to each task. The specificity of our method means it can have an impact on the understanding of psychiatric disorders, which are believed to be related to highly specific communication between brain regions compared to controls. In sum, we propose a general model for dynamic communication learning on graphs, and show its applicability to a subfield of the natural sciences, with potential widespread scientific impact.
Spatio-temporally separable non-linear latent factor learning: an application to somatomotor cortex fMRI data
May 26, 2022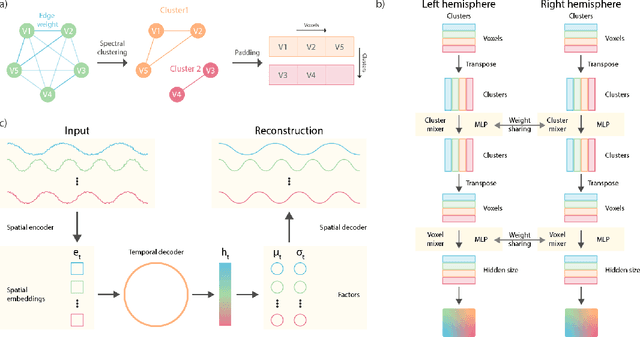
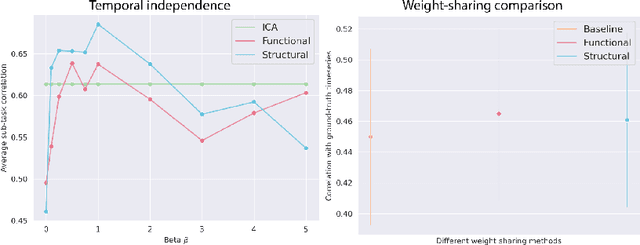
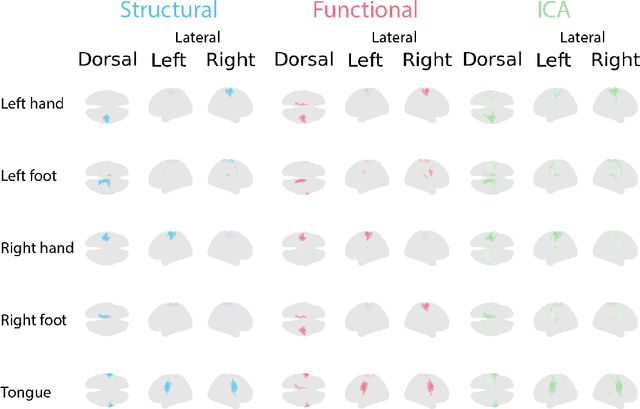
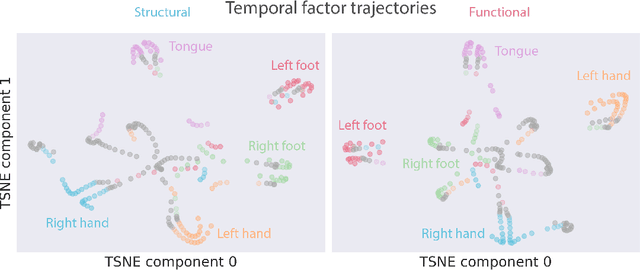
Functional magnetic resonance imaging (fMRI) data contain complex spatiotemporal dynamics, thus researchers have developed approaches that reduce the dimensionality of the signal while extracting relevant and interpretable dynamics. Models of fMRI data that can perform whole-brain discovery of dynamical latent factors are understudied. The benefits of approaches such as linear independent component analysis models have been widely appreciated, however, nonlinear extensions of these models present challenges in terms of identification. Deep learning methods provide a way forward, but new methods for efficient spatial weight-sharing are critical to deal with the high dimensionality of the data and the presence of noise. Our approach generalizes weight sharing to non-Euclidean neuroimaging data by first performing spectral clustering based on the structural and functional similarity between voxels. The spectral clusters and their assignments can then be used as patches in an adapted multi-layer perceptron (MLP)-mixer model to share parameters among input points. To encourage temporally independent latent factors, we use an additional total correlation term in the loss. Our approach is evaluated on data with multiple motor sub-tasks to assess whether the model captures disentangled latent factors that correspond to each sub-task. Then, to assess the latent factors we find further, we compare the spatial location of each latent factor to the motor homunculus. Finally, we show that our approach captures task effects better than the current gold standard of source signal separation, independent component analysis (ICA).