 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoencoders in Function Space
Aug 02, 2024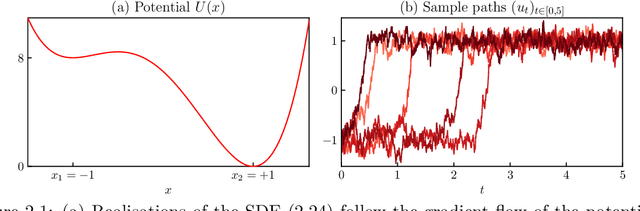
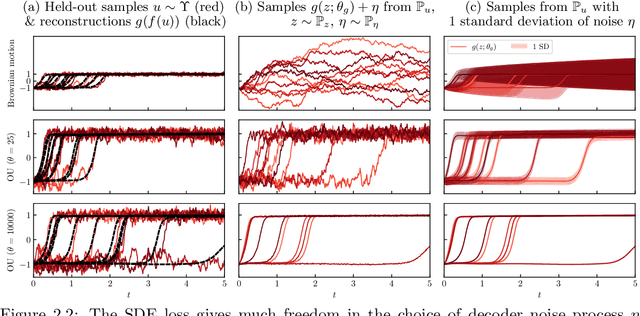
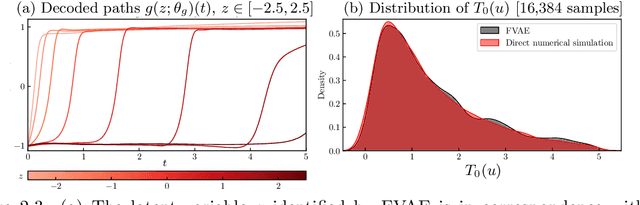
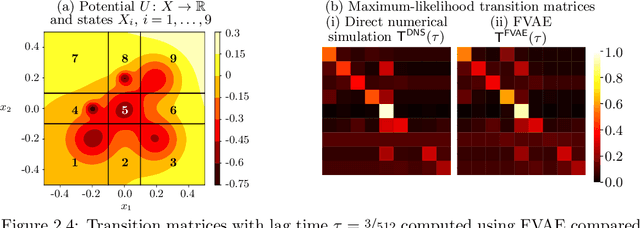
Autoencoders have found widespread application, in both their original deterministic form and in their variational formulation (VAEs). In scientific applications it is often of interest to consider data that are comprised of functions; the same perspective is useful in image processing. In practice, discretisation (of differential equations arising in the sciences) or pixellation (of images) renders problems finite dimensional, but conceiving first of algorithms that operate on functions, and only then discretising or pixellating, leads to better algorithms that smoothly operate between different levels of discretisation or pixellation. In this paper function-space versions of the autoencoder (FAE) and variational autoencoder (FVAE) are introduced, analysed, and deployed. Well-definedness of the objective function governing VAEs is a subtle issue, even in finite dimension, and more so on function space. The FVAE objective is well defined whenever the data distribution is compatible with the chosen generative model; this happens, for example, when the data arise from a stochastic differential equation. The FAE objective is valid much more broadly, and can be straightforwardly applied to data governed by differential equations. Pairing these objectives with neural operator architectures, which can thus be evaluated on any mesh, enables new applications of autoencoders to inpainting, superresolution, and generative modelling of scientific data.
Learning linear operators: Infinite-dimensional regression as a well-behaved non-compact inverse problem
Nov 16, 2022We consider the problem of learning a linear operator $\theta$ between two Hilbert spaces from empirical observations, which we interpret as least squares regression in infinite dimensions. We show that this goal can be reformulated as an inverse problem for $\theta$ with the undesirable feature that its forward operator is generally non-compact (even if $\theta$ is assumed to be compact or of $p$-Schatten class). However, we prove that, in terms of spectral properties and regularisation theory, this inverse problem is equivalent to the known compact inverse problem associated with scalar response regression. Our framework allows for the elegant derivation of dimension-free rates for generic learning algorithms under H\"older-type source conditions. The proofs rely on the combination of techniques from kernel regression with recent results on concentration of measure for sub-exponential Hilbertian random variables. The obtained rates hold for a variety of practically-relevant scenarios in functional regression as well as nonlinear regression with operator-valued kernels and match those of classical kernel regression with scalar response.
Bayesian Numerical Methods for Nonlinear Partial Differential Equations
May 03, 2021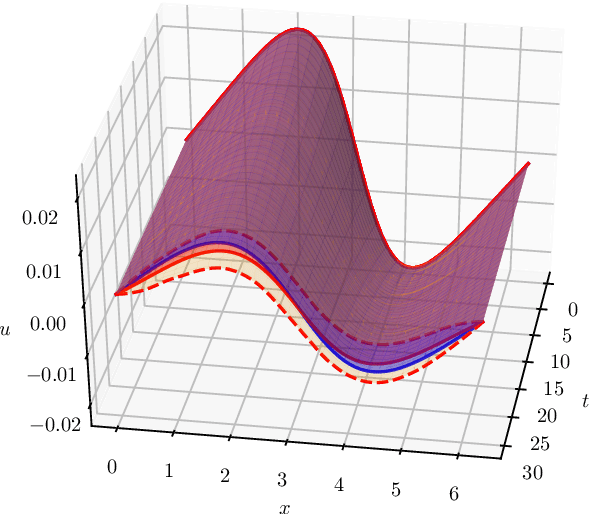
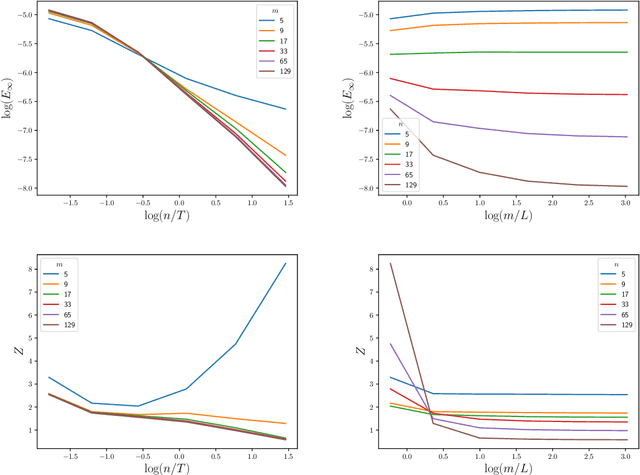
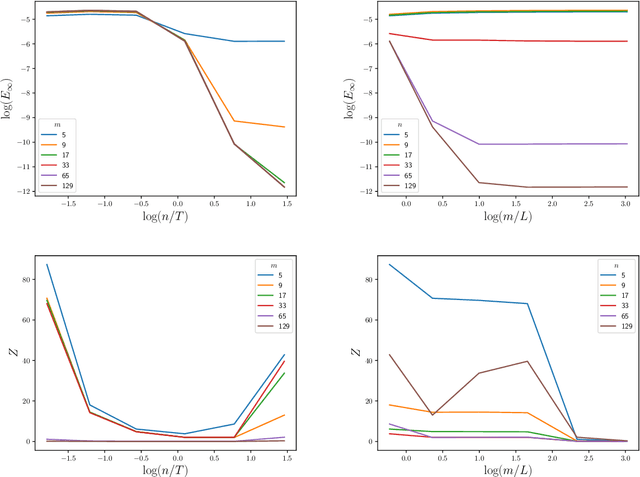
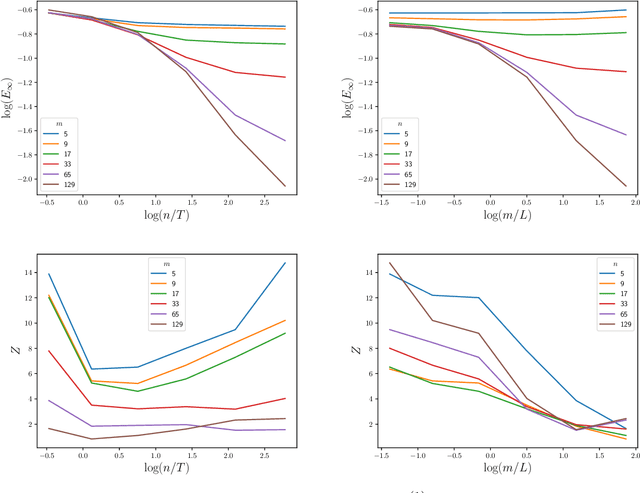
The numerical solution of differential equations can be formulated as an inference problem to which formal statistical approaches can be applied. However, nonlinear partial differential equations (PDEs) pose substantial challenges from an inferential perspective, most notably the absence of explicit conditioning formula. This paper extends earlier work on linear PDEs to a general class of initial value problems specified by nonlinear PDEs, motivated by problems for which evaluations of the right-hand-side, initial conditions, or boundary conditions of the PDE have a high computational cost. The proposed method can be viewed as exact Bayesian inference under an approximate likelihood, which is based on discretisation of the nonlinear differential operator. Proof-of-concept experimental results demonstrate that meaningful probabilistic uncertainty quantification for the unknown solution of the PDE can be performed, while controlling the number of times the right-hand-side, initial and boundary conditions are evaluated. A suitable prior model for the solution of the PDE is identified using novel theoretical analysis of the sample path properties of Mat\'{e}rn processes, which may be of independent interest.
The linear conditional expectation in Hilbert space
Aug 27, 2020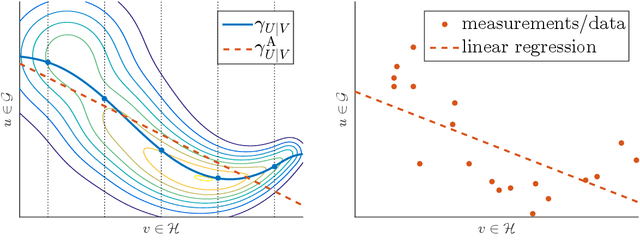


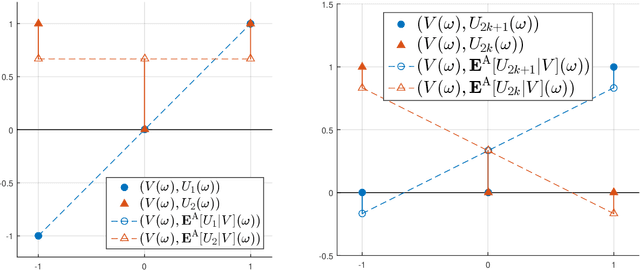
The linear conditional expectation (LCE) provides a best linear (or rather, affine) estimate of the conditional expectation and hence plays an important r\^ole in approximate Bayesian inference, especially the Bayes linear approach. This article establishes the analytical properties of the LCE in an infinite-dimensional Hilbert space context. In addition, working in the space of affine Hilbert--Schmidt operators, we establish a regularisation procedure for this LCE. As an important application, we obtain a simple alternative derivation and intuitive justification of the conditional mean embedding formula, a concept widely used in machine learning to perform the conditioning of random variables by embedding them into reproducing kernel Hilbert spaces.
A Rigorous Theory of Conditional Mean Embeddings
Dec 16, 2019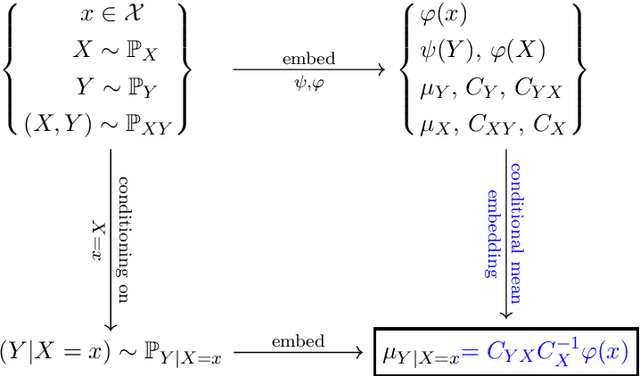
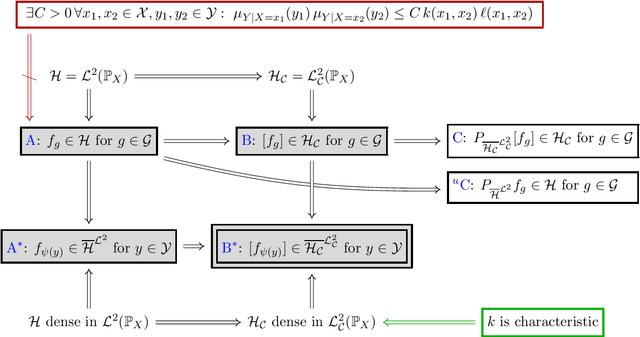
Conditional mean embeddings (CME) have proven themselves to be a powerful tool in many machine learning applications. They allow the efficient conditioning of probability distributions within the corresponding reproducing kernel Hilbert spaces (RKHSs) by providing a linear-algebraic relation for the kernel mean embeddings of the respective probability distributions. Both centered and uncentered covariance operators have been used to define CMEs in the existing literature. In this paper, we develop a mathematically rigorous theory for both variants, discuss the merits and problems of either, and significantly weaken the conditions for applicability of CMEs. In the course of this, we demonstrate a beautiful connection to Gaussian conditioning in Hilbert spaces.
A Modern Retrospective on Probabilistic Numerics
Jan 14, 2019

This article attempts to cast the emergence of probabilistic numerics as a mathematical-statistical research field within its historical context and to explore how its gradual development can be related to modern formal treatments and applications. We highlight in particular the parallel contributions of Sul'din and Larkin in the 1960s and how their pioneering early ideas have reached a degree of maturity in the intervening period, mediated by paradigms such as average-case analysis and information-based complexity. We provide a subjective assessment of the state of research in probabilistic numerics and highlight some difficulties to be addressed by future works.
Convergence Rates of Gaussian ODE Filters
Jul 25, 2018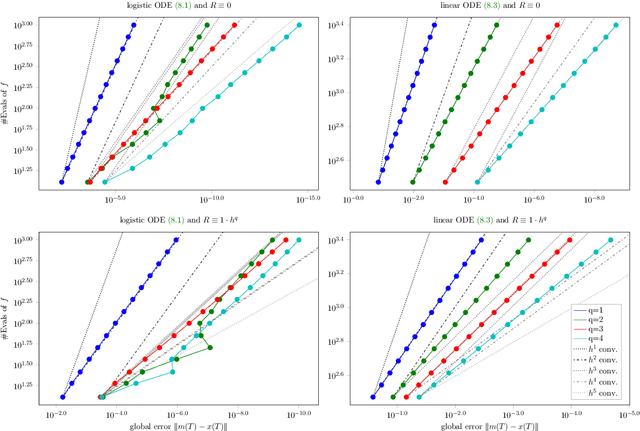
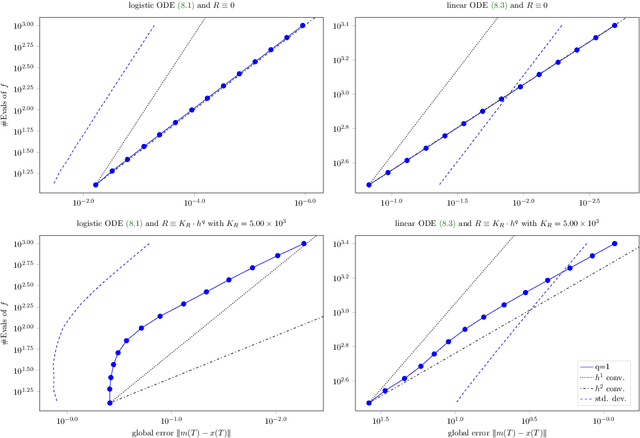
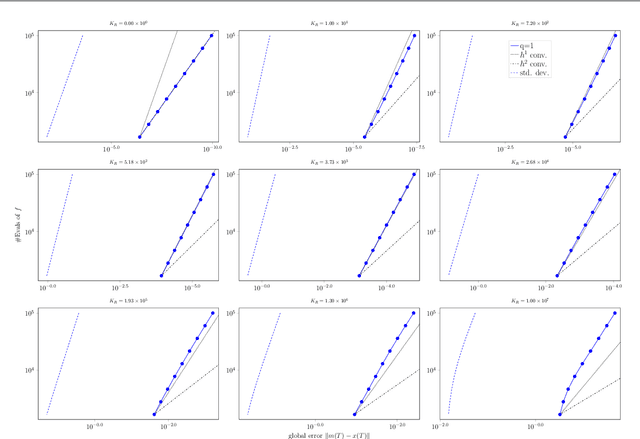
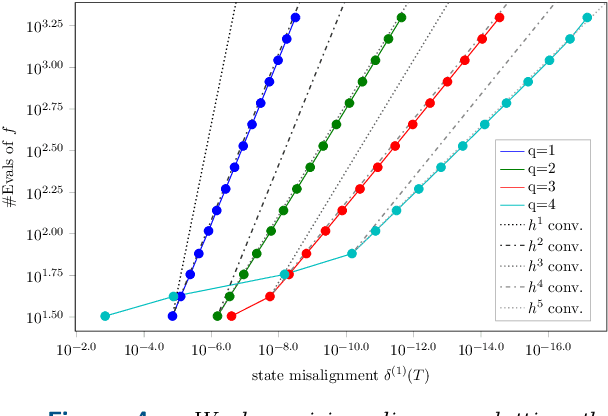
A recently-introduced class of probabilistic (uncertainty-aware) solvers for ordinary differential equations (ODEs) applies Gaussian (Kalman) filtering to initial value problems. These methods model the true solution $x$ and its first $q$ derivatives a priori as a Gauss--Markov process $\boldsymbol{X}$, which is then iteratively conditioned on information about $\dot{x}$. We prove worst-case local convergence rates of order $h^{q+1}$ for a wide range of versions of this Gaussian ODE filter, as well as global convergence rates of order $h^q$ in the case of $q=1$ and an integrated Brownian motion prior, and analyze how inaccurate information on $\dot{x}$ coming from approximate evaluations of $f$ affects these rates. Moreover, we present explicit formulas for the steady states and show that the posterior confidence intervals are well calibrated in all considered cases that exhibit global convergence---in the sense that they globally contract at the same rate as the truncation error.