 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompGS++: Compressed Gaussian Splatting for Static and Dynamic Scene Representation
Apr 17, 2025


Gaussian splatting demonstrates proficiency for 3D scene modeling but suffers from substantial data volume due to inherent primitive redundancy. To enable future photorealistic 3D immersive visual communication applications, significant compression is essential for transmission over the existing Internet infrastructure. Hence, we propose Compressed Gaussian Splatting (CompGS++), a novel framework that leverages compact Gaussian primitives to achieve accurate 3D modeling with substantial size reduction for both static and dynamic scenes. Our design is based on the principle of eliminating redundancy both between and within primitives. Specifically, we develop a comprehensive prediction paradigm to address inter-primitive redundancy through spatial and temporal primitive prediction modules. The spatial primitive prediction module establishes predictive relationships for scene primitives and enables most primitives to be encoded as compact residuals, substantially reducing the spatial redundancy. We further devise a temporal primitive prediction module to handle dynamic scenes, which exploits primitive correlations across timestamps to effectively reduce temporal redundancy. Moreover, we devise a rate-constrained optimization module that jointly minimizes reconstruction error and rate consumption. This module effectively eliminates parameter redundancy within primitives and enhances the overall compactness of scene representations. Comprehensive evaluations across multiple benchmark datasets demonstrate that CompGS++ significantly outperforms existing methods, achieving superior compression performance while preserving accurate scene modeling. Our implementation will be made publicly available on GitHub to facilitate further research.
CompGS: Efficient 3D Scene Representation via Compressed Gaussian Splatting
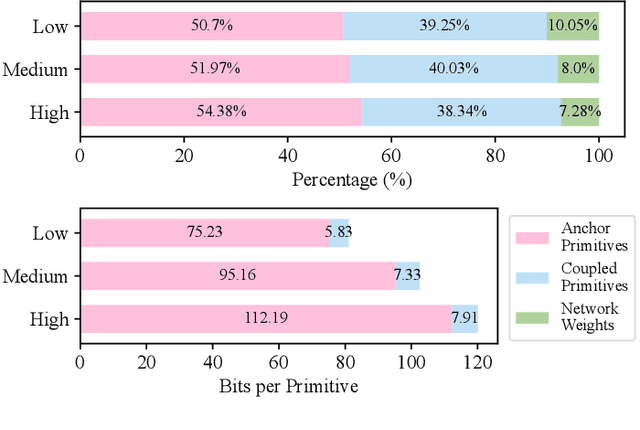
Apr 15, 2024Gaussian splatting, renowned for its exceptional rendering quality and efficiency, has emerged as a prominent technique in 3D scene representation. However, the substantial data volume of Gaussian splatting impedes its practical utility in real-world applications. Herein, we propose an efficient 3D scene representation, named Compressed Gaussian Splatting (CompGS), which harnesses compact Gaussian primitives for faithful 3D scene modeling with a remarkably reduced data size. To ensure the compactness of Gaussian primitives, we devise a hybrid primitive structure that captures predictive relationships between each other. Then, we exploit a small set of anchor primitives for prediction, allowing the majority of primitives to be encapsulated into highly compact residual forms. Moreover, we develop a rate-constrained optimization scheme to eliminate redundancies within such hybrid primitives, steering our CompGS towards an optimal trade-off between bitrate consumption and representation efficacy. Experimental results show that the proposed CompGS significantly outperforms existing methods, achieving superior compactness in 3D scene representation without compromising model accuracy and rendering quality. Our code will be released on GitHub for further research.
Geometric Prior Based Deep Human Point Cloud Geometry Compression
May 02, 2023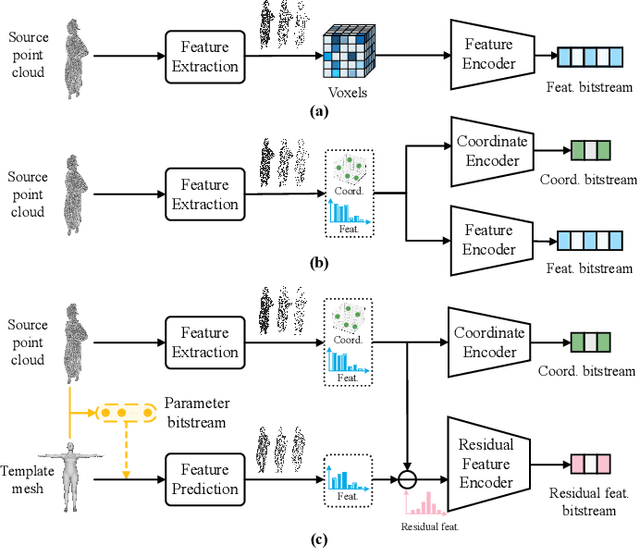



The emergence of digital avatars has raised an exponential increase in the demand for human point clouds with realistic and intricate details. The compression of such data becomes challenging with overwhelming data amounts comprising millions of points. Herein, we leverage the human geometric prior in geometry redundancy removal of point clouds, greatly promoting the compression performance. More specifically, the prior provides topological constraints as geometry initialization, allowing adaptive adjustments with a compact parameter set that could be represented with only a few bits. Therefore, we can envisage high-resolution human point clouds as a combination of geometric priors and structural deviations. The priors could first be derived with an aligned point cloud, and subsequently the difference of features is compressed into a compact latent code. The proposed framework can operate in a play-and-plug fashion with existing learning based point cloud compression methods. Extensive experimental results show that our approach significantly improves the compression performance without deteriorating the quality, demonstrating its promise in a variety of applications.