 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr.Hair: Reconstructing Scalp-Connected Hair Strands without Pre-training via Differentiable Rendering of Line Segments
Mar 29, 2024

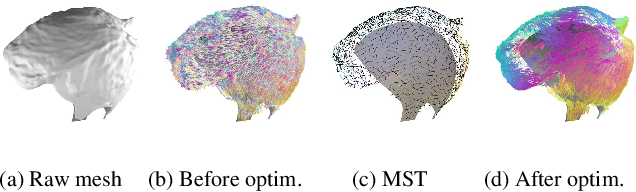

In the film and gaming industries, achieving a realistic hair appearance typically involves the use of strands originating from the scalp. However, reconstructing these strands from observed surface images of hair presents significant challenges. The difficulty in acquiring Ground Truth (GT) data has led state-of-the-art learning-based methods to rely on pre-training with manually prepared synthetic CG data. This process is not only labor-intensive and costly but also introduces complications due to the domain gap when compared to real-world data. In this study, we propose an optimization-based approach that eliminates the need for pre-training. Our method represents hair strands as line segments growing from the scalp and optimizes them using a novel differentiable rendering algorithm. To robustly optimize a substantial number of slender explicit geometries, we introduce 3D orientation estimation utilizing global optimization, strand initialization based on Laplace's equation, and reparameterization that leverages geometric connectivity and spatial proximity. Unlike existing optimization-based methods, our method is capable of reconstructing internal hair flow in an absolute direction. Our method exhibits robust and accurate inverse rendering, surpassing the quality of existing methods and significantly improving processing speed.
Dressi: A Hardware-Agnostic Differentiable Renderer with Reactive Shader Packing and Soft Rasterization
Apr 04, 2022
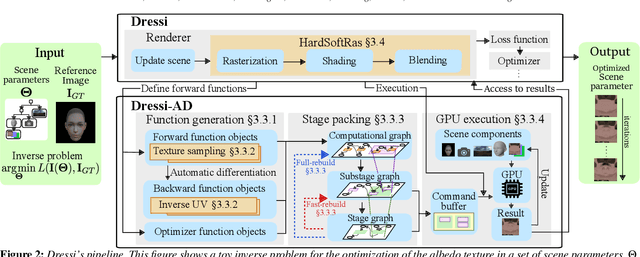
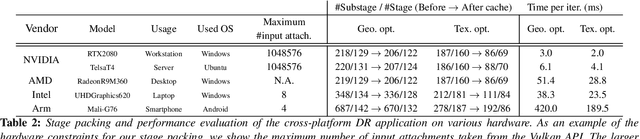
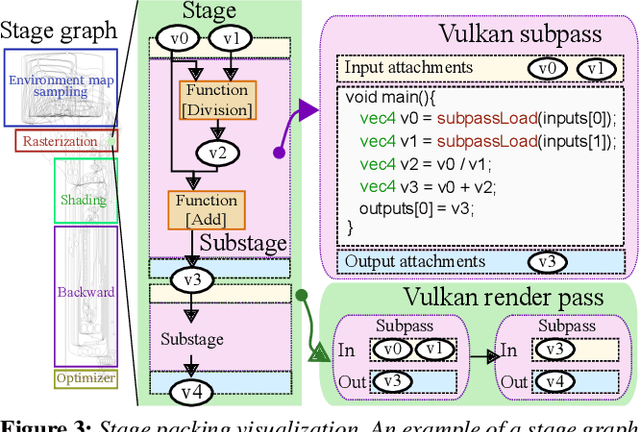
Differentiable rendering (DR) enables various computer graphics and computer vision applications through gradient-based optimization with derivatives of the rendering equation. Most rasterization-based approaches are built on general-purpose automatic differentiation (AD) libraries and DR-specific modules handcrafted using CUDA. Such a system design mixes DR algorithm implementation and algorithm building blocks, resulting in hardware dependency and limited performance. In this paper, we present a practical hardware-agnostic differentiable renderer called Dressi, which is based on a new full AD design. The DR algorithms of Dressi are fully written in our Vulkan-based AD for DR, Dressi-AD, which supports all primitive operations for DR. Dressi-AD and our inverse UV technique inside it bring hardware independence and acceleration by graphics hardware. Stage packing, our runtime optimization technique, can adapt hardware constraints and efficiently execute complex computational graphs of DR with reactive cache considering the render pass hierarchy of Vulkan. HardSoftRas, our novel rendering process, is designed for inverse rendering with a graphics pipeline. Under the limited functionalities of the graphics pipeline, HardSoftRas can propagate the gradients of pixels from the screen space to far-range triangle attributes. Our experiments and applications demonstrate that Dressi establishes hardware independence, high-quality and robust optimization with fast speed, and photorealistic rendering.
4DComplete: Non-Rigid Motion Estimation Beyond the Observable Surface
May 05, 2021
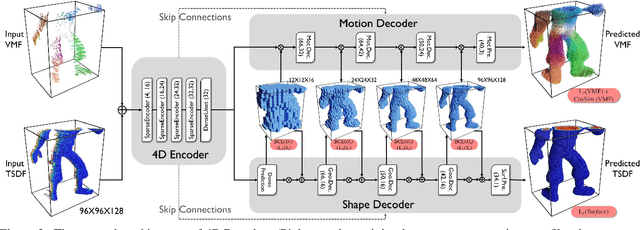

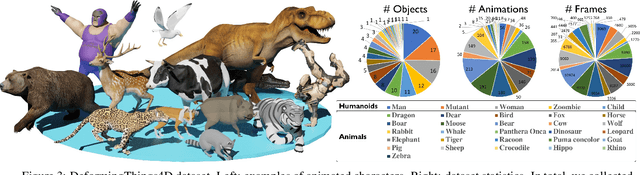
Tracking non-rigidly deforming scenes using range sensors has numerous applications including computer vision, AR/VR, and robotics. However, due to occlusions and physical limitations of range sensors, existing methods only handle the visible surface, thus causing discontinuities and incompleteness in the motion field. To this end, we introduce 4DComplete, a novel data-driven approach that estimates the non-rigid motion for the unobserved geometry. 4DComplete takes as input a partial shape and motion observation, extracts 4D time-space embedding, and jointly infers the missing geometry and motion field using a sparse fully-convolutional network. For network training, we constructed a large-scale synthetic dataset called DeformingThings4D, which consists of 1972 animation sequences spanning 31 different animals or humanoid categories with dense 4D annotation. Experiments show that 4DComplete 1) reconstructs high-resolution volumetric shape and motion field from a partial observation, 2) learns an entangled 4D feature representation that benefits both shape and motion estimation, 3) yields more accurate and natural deformation than classic non-rigid priors such as As-Rigid-As-Possible (ARAP) deformation, and 4) generalizes well to unseen objects in real-world sequences.