 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropRegion Training of Inception Font Network for High-Performance Chinese Font Recognition
Mar 27, 2017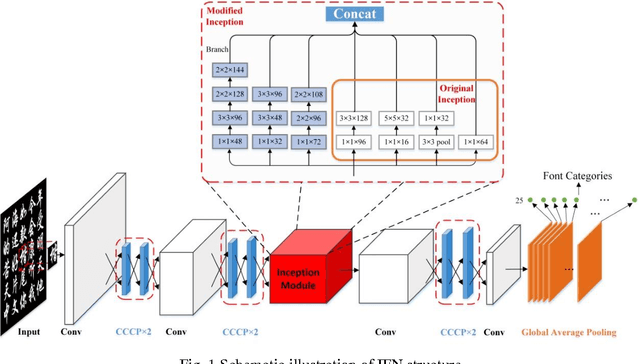
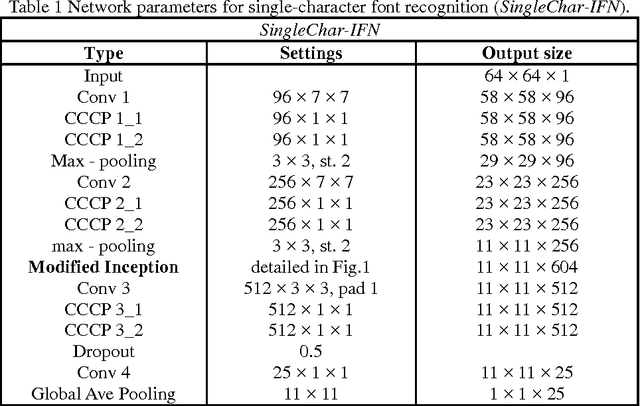

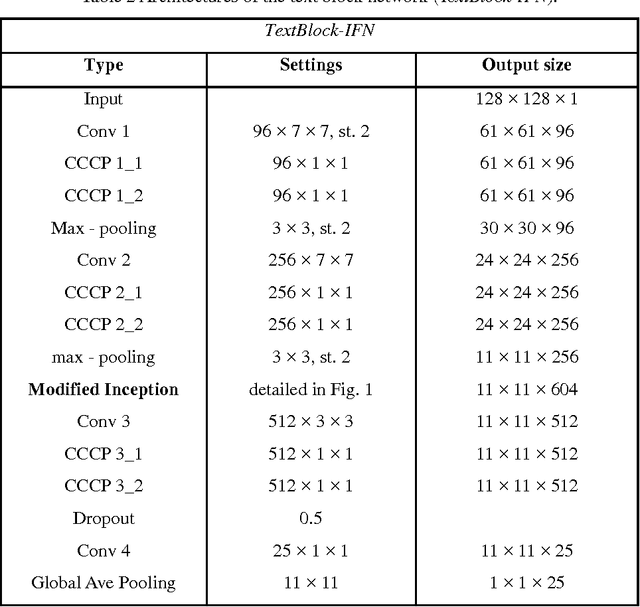
Chinese font recognition (CFR) has gained significant attention in recent years. However, due to the sparsity of labeled font samples and the structural complexity of Chinese characters, CFR is still a challenging task. In this paper, a DropRegion method is proposed to generate a large number of stochastic variant font samples whose local regions are selectively disrupted and an inception font network (IFN) with two additional convolutional neural network (CNN) structure elements, i.e., a cascaded cross-channel parametric pooling (CCCP) and global average pooling, is designed. Because the distribution of strokes in a font image is non-stationary, an elastic meshing technique that adaptively constructs a set of local regions with equalized information is developed. Thus, DropRegion is seamlessly embedded in the IFN, which enables end-to-end training; the proposed DropRegion-IFN can be used for high performance CFR. Experimental results have confirmed the effectiveness of our new approach for CFR.
DeepText: A Unified Framework for Text Proposal Generation and Text Detection in Natural Images
May 24, 2016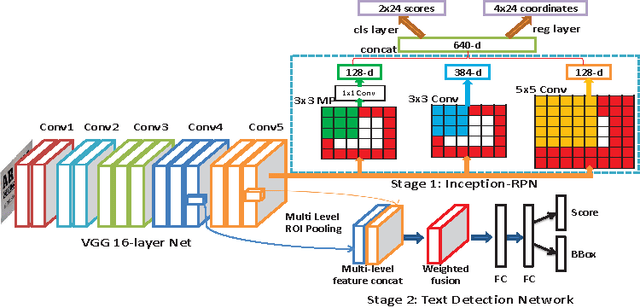
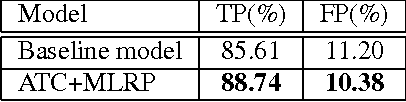

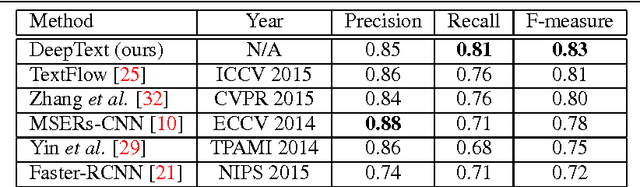
In this paper, we develop a novel unified framework called DeepText for text region proposal generation and text detection in natural images via a fully convolutional neural network (CNN). First, we propose the inception region proposal network (Inception-RPN) and design a set of text characteristic prior bounding boxes to achieve high word recall with only hundred level candidate proposals. Next, we present a powerful textdetection network that embeds ambiguous text category (ATC) information and multilevel region-of-interest pooling (MLRP) for text and non-text classification and accurate localization. Finally, we apply an iterative bounding box voting scheme to pursue high recall in a complementary manner and introduce a filtering algorithm to retain the most suitable bounding box, while removing redundant inner and outer boxes for each text instance. Our approach achieves an F-measure of 0.83 and 0.85 on the ICDAR 2011 and 2013 robust text detection benchmarks, outperforming previous state-of-the-art results.
Fully Convolutional Recurrent Network for Handwritten Chinese Text Recognition
Apr 18, 2016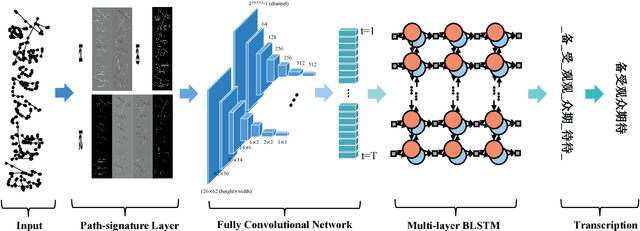
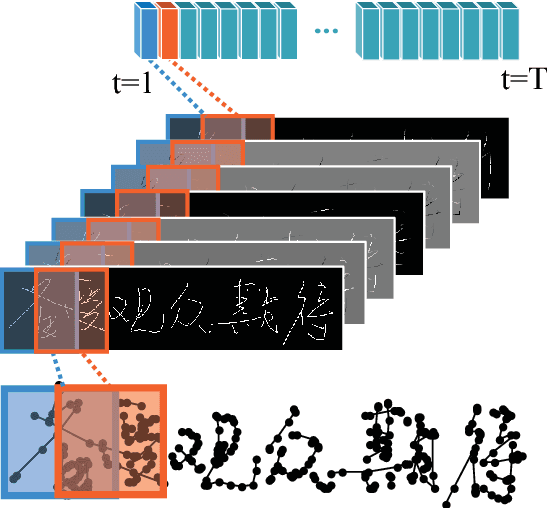
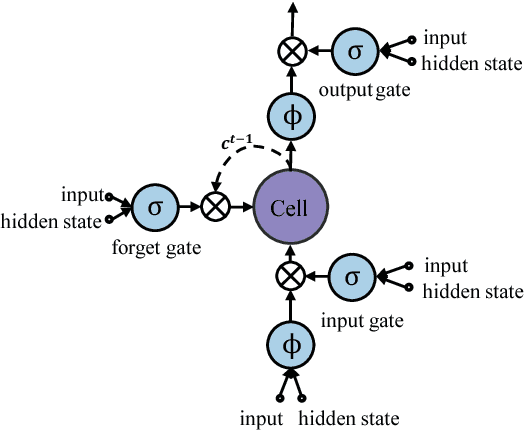

This paper proposes an end-to-end framework, namely fully convolutional recurrent network (FCRN) for handwritten Chinese text recognition (HCTR). Unlike traditional methods that rely heavily on segmentation, our FCRN is trained with online text data directly and learns to associate the pen-tip trajectory with a sequence of characters. FCRN consists of four parts: a path-signature layer to extract signature features from the input pen-tip trajectory, a fully convolutional network to learn informative representation, a sequence modeling layer to make per-frame predictions on the input sequence and a transcription layer to translate the predictions into a label sequence. The FCRN is end-to-end trainable in contrast to conventional methods whose components are separately trained and tuned. We also present a refined beam search method that efficiently integrates the language model to decode the FCRN and significantly improve the recognition results. We evaluate the performance of the proposed method on the test sets from the databases CASIA-OLHWDB and ICDAR 2013 Chinese handwriting recognition competition, and both achieve state-of-the-art performance with correct rates of 96.40% and 95.00%, respectively.
Character Proposal Network for Robust Text Extraction
Feb 13, 2016
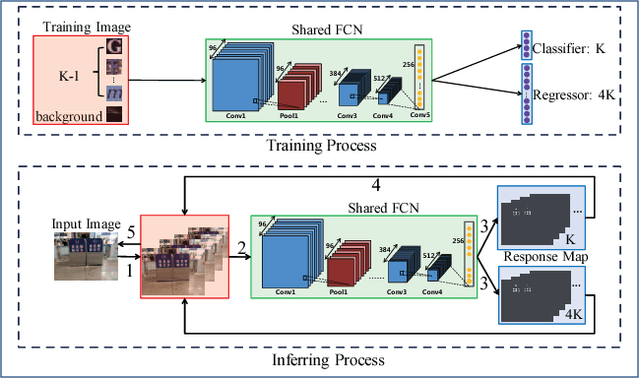

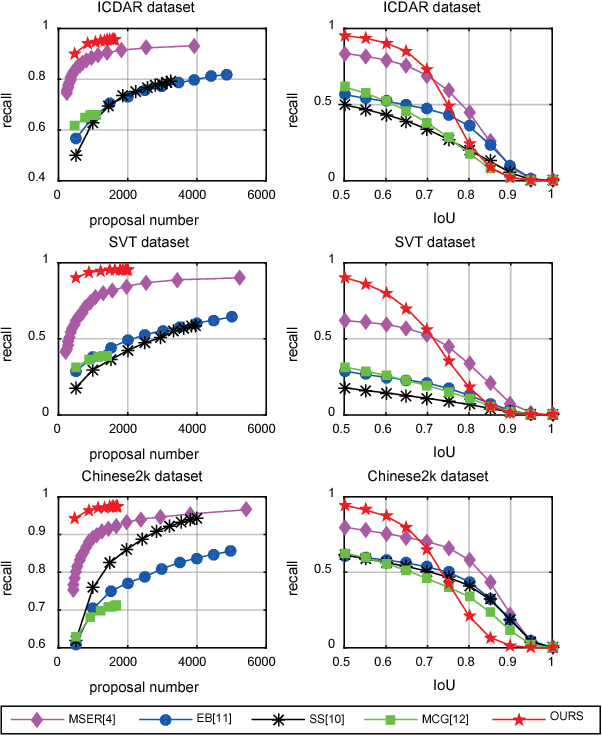
Maximally stable extremal regions (MSER), which is a popular method to generate character proposals/candidates, has shown superior performance in scene text detection. However, the pixel-level operation limits its capability for handling some challenging cases (e.g., multiple connected characters, separated parts of one character and non-uniform illumination). To better tackle these cases, we design a character proposal network (CPN) by taking advantage of the high capacity and fast computing of fully convolutional network (FCN). Specifically, the network simultaneously predicts characterness scores and refines the corresponding locations. The characterness scores can be used for proposal ranking to reject non-character proposals and the refining process aims to obtain the more accurate locations. Furthermore, considering the situation that different characters have different aspect ratios, we propose a multi-template strategy, designing a refiner for each aspect ratio. The extensive experiments indicate our method achieves recall rates of 93.88%, 93.60% and 96.46% on ICDAR 2013, SVT and Chinese2k datasets respectively using less than 1000 proposals, demonstrating promising performance of our character proposal network.
Recognition Confidence Analysis of Handwritten Chinese Character with CNN
May 25, 2015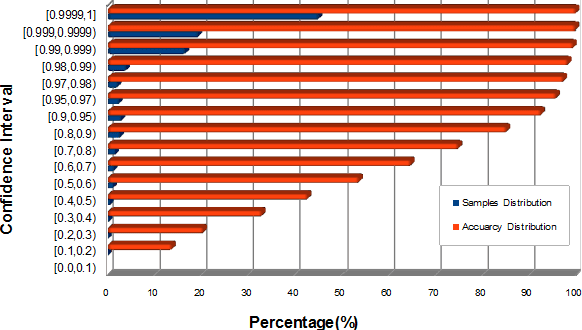


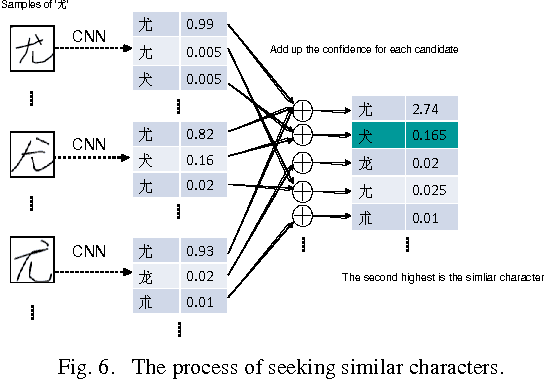
In this paper, we present an effective method to analyze the recognition confidence of handwritten Chinese character, based on the softmax regression score of a high performance convolutional neural networks (CNN). Through careful and thorough statistics of 827,685 testing samples that randomly selected from total 8836 different classes of Chinese characters, we find that the confidence measurement based on CNN is an useful metric to know how reliable the recognition results are. Furthermore, we find by experiments that the recognition confidence can be used to find out similar and confusable character-pairs, to check wrongly or cursively written samples, and even to discover and correct mis-labelled samples. Many interesting observations and statistics are given and analyzed in this study.